Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
List of notation
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 768-768
-
- Chapter
- Export citation
Appendix
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 701-702
-
- Chapter
- Export citation
24 - Applications
- from V - Hilbert
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 677-700
-
- Chapter
- Export citation
14 - Factoring polynomials over finite fields
- from III - Gauß
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 377-432
-
- Chapter
- Export citation
12 - Fast linear algebra
- from II - Newton
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 335-358
-
- Chapter
- Export citation
II - Newton
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 217-220
-
- Chapter
- Export citation
17 - Applications of basis reduction
- from III - Gauß
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 503-510
-
- Chapter
- Export citation
References
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 734-767
-
- Chapter
- Export citation
Abelian periods, partial words, and an extension of a theoremof Fine and Wilf∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 3 / July 2013
- Published online by Cambridge University Press:
- 25 April 2013, pp. 215-234
- Print publication:
- July 2013
-
- Article
- Export citation
21 - Gröbner bases
- from V - Hilbert
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 591-622
-
- Chapter
- Export citation
Sources of illustrations
-
- Book:
- Modern Computer Algebra
- Published online:
- 05 May 2013
- Print publication:
- 25 April 2013, pp 725-725
-
- Chapter
- Export citation
Expansion in High Dimension for the Growth Constants of Lattice Trees and Lattice Animals
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 15 April 2013, pp. 527-565
-
- Article
- Export citation
-
We compute the first three terms of the 1/d expansions for the growth constants and one-point functions of nearest-neighbour lattice trees and lattice (bond) animals on the integer lattice
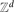 $\mathbb{Z}^d$, with rigorous error estimates. The proof uses the lace expansion, together with a new expansion for the one-point functions based on inclusion–exclusion.
$\mathbb{Z}^d$, with rigorous error estimates. The proof uses the lace expansion, together with a new expansion for the one-point functions based on inclusion–exclusion.
On the Swap-Distances of Different Realizations of a Graphical Degree Sequence
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 05 April 2013, pp. 366-383
-
- Article
- Export citation
CPC volume 22 issue 3 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 05 April 2013, pp. b1-b6
-
- Article
-
- You have access
- Export citation
Normal Numbers and the Normality Measure
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 05 April 2013, pp. 342-345
-
- Article
- Export citation
-
In a paper published in this journal, Alon, Kohayakawa, Mauduit, Moreira and Rödl proved that the minimal possible value of the normality measure of an N-element binary sequence satisfies
for sufficiently large N, and conjectured that the lower bound can be improved to some power of N. In this note it is observed that a construction of Levin of a normal number having small discrepancy gives a construction of a binary sequence EN with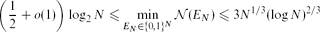 \begin{equation*}\biggl( \frac{1}{2} + o(1) \biggr) \log_2 N \leq \min_{E_N \in \{0,1\}^N} \mathcal{N}(E_N) \leq 3 N^{1/3} (\log N)^{2/3}\end{equation*}
\begin{equation*}\biggl( \frac{1}{2} + o(1) \biggr) \log_2 N \leq \min_{E_N \in \{0,1\}^N} \mathcal{N}(E_N) \leq 3 N^{1/3} (\log N)^{2/3}\end{equation*}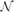
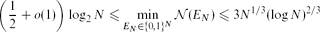
CPC volume 22 issue 3 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 05 April 2013, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Decidability of the HD0L ultimateperiodicity problem
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 25 April 2013, pp. 201-214
- Print publication:
- April 2013
-
- Article
- Export citation
A note on constructing infinite binary words with polynomial subword complexity∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 25 April 2013, pp. 195-199
- Print publication:
- April 2013
-
- Article
- Export citation
Arithmetic Progressions in Sumsets and Lp-Almost-Periodicity
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 3 / May 2013
- Published online by Cambridge University Press:
- 19 March 2013, pp. 351-365
-
- Article
- Export citation
-
We prove results about the Lp-almost-periodicity of convolutions. One of these follows from a simple but rather general lemma about approximating a sum of functions in Lp, and gives a very short proof of a theorem of Green that if A and B are subsets of {1,. . .,N} of sizes αN and βN then A+B contains an arithmetic progression of length at least
Another almost-periodicity result improves this bound for densities decreasing with N: we show that under the above hypotheses the sumset A+B contains an arithmetic progression of length at least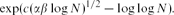 \begin{equation}\exp ( c (\alpha \beta \log N)^{1/2} - \log\log N).\end{equation}
\begin{equation}\exp ( c (\alpha \beta \log N)^{1/2} - \log\log N).\end{equation}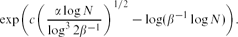 \begin{equation}\exp\biggl( c \biggl(\frac{\alpha \log N}{\log^3 2\beta^{-1}} \biggr)^{1/2} - \log( \beta^{-1} \log N) \biggr).\end{equation}
\begin{equation}\exp\biggl( c \biggl(\frac{\alpha \log N}{\log^3 2\beta^{-1}} \biggr)^{1/2} - \log( \beta^{-1} \log N) \biggr).\end{equation}
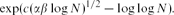
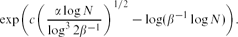
Cutwidth of iterated caterpillars∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 47 / Issue 2 / April 2013
- Published online by Cambridge University Press:
- 11 March 2013, pp. 181-193
- Print publication:
- April 2013
-
- Article
- Export citation
