Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
CPC volume 21 issue 6 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 27 September 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Dense Graphs With a Large Triangle Cover Have a Large Triangle Packing
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 27 September 2012, pp. 952-962
-
- Article
- Export citation
-
It is well known that a graph with m edges can be made triangle-free by removing (slightly less than) m/2 edges. On the other hand, there are many classes of graphs which are hard to make triangle-free, in the sense that it is necessary to remove roughly m/2 edges in order to eliminate all triangles.
We prove that dense graphs that are hard to make triangle-free have a large packing of pairwise edge-disjoint triangles. In particular, they have more than m(1/4+cβ) pairwise edge-disjoint triangles where β is the density of the graph and c ≥
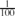
We extend our result from triangles to larger cliques and odd cycles.
CPC volume 21 issue 6 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 27 September 2012, pp. b1-b2
-
- Article
-
- You have access
- Export citation
(k+1)-Cores Have k-Factors
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 11 September 2012, pp. 882-896
-
- Article
- Export citation
Fast Strategies In Maker–Breaker Games Played on Random Boards
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 10 September 2012, pp. 897-915
-
- Article
- Export citation
-
In this paper we analyse classical Maker–Breaker games played on the edge set of a sparse random board G ~
References
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 261-263
-
- Chapter
- Export citation
8 - Tame Hypermap
- from PART THREE - THE KEPLER CONJECTURE
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 235-256
-
- Chapter
- Export citation
2 - Trigonometry
- from PART TWO - FOUNDATIONS
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 25-60
-
- Chapter
- Export citation
Appendix A - Credits
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 257-260
-
- Chapter
- Export citation
Notation index
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 269-271
-
- Chapter
- Export citation
PART THREE - THE KEPLER CONJECTURE
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 143-144
-
- Chapter
- Export citation
1 - Close Packing
- from PART ONE - OVERVIEW
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 3-22
-
- Chapter
- Export citation
4 - Hypermap
- from PART TWO - FOUNDATIONS
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 72-111
-
- Chapter
- Export citation
7 - Local Fan
- from PART THREE - THE KEPLER CONJECTURE
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 194-234
-
- Chapter
- Export citation
PART TWO - FOUNDATIONS
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 23-24
-
- Chapter
- Export citation
6 - Packing
- from PART THREE - THE KEPLER CONJECTURE
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 145-193
-
- Chapter
- Export citation
PART ONE - OVERVIEW
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 1-2
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp i-iv
-
- Chapter
- Export citation
Preface
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp vii-xiv
-
- Chapter
- Export citation
General index
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 264-268
-
- Chapter
- Export citation
