Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
5 - Fan
- from PART TWO - FOUNDATIONS
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 112-142
-
- Chapter
- Export citation
3 - Volume
- from PART TWO - FOUNDATIONS
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp 61-71
-
- Chapter
- Export citation
Contents
-
- Book:
- Dense Sphere Packings
- Published online:
- 05 October 2012
- Print publication:
- 06 September 2012, pp v-vi
-
- Chapter
- Export citation
On (Not) Computing the Möbius Function Using Bounded Depth Circuits
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 24 August 2012, pp. 942-951
-
- Article
- Export citation
-
Any function F: {0,. . ., N − 1} → {−1,1} such that F(x) can be computed from the binary digits of x using a bounded depth circuit is orthogonal to the Möbius function μ in the sense that
The proof combines a result of Linial, Mansour and Nisan with techniques of Kátai and Harman, used in their work on finding primes with specified digits.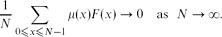 \[\frac{1}{N} \sum_{0 \leq x \leq N-1} \mu(x)F(x) → 0 \quad\text{as}~~ N → \infty.\]
\[\frac{1}{N} \sum_{0 \leq x \leq N-1} \mu(x)F(x) → 0 \quad\text{as}~~ N → \infty.\]
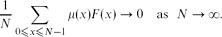
Cops and Robbers on Geometric Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 16 August 2012, pp. 816-834
-
- Article
- Export citation
-
Cops and robbers is a turn-based pursuit game played on a graph G. One robber is pursued by a set of cops. In each round, these agents move between vertices along the edges of the graph. The cop number c(G) denotes the minimum number of cops required to catch the robber in finite time. We study the cop number of geometric graphs. For points x1, . . ., xn ∈ ℝ2, and r ∈ ℝ+, the vertex set of the geometric graph G(x1, . . ., xn; r) is the graph on these n points, with xi, xj adjacent when ∥xi − xj∥ ≤ r. We prove that c(G) ≤ 9 for any connected geometric graph G in ℝ2 and we give an example of a connected geometric graph with c(G) = 3. We improve on our upper bound for random geometric graphs that are sufficiently dense. Let
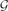
Testing Odd-Cycle-Freeness in Boolean Functions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 10 August 2012, pp. 835-855
-
- Article
- Export citation
-
A function f:

The first issue we study is directly reducing testing of linear-invariant properties of Boolean functions to testing associated graph properties. We show a black-box reduction from testing odd-cycle-freeness to testing bipartiteness of graphs. Such reductions have already been shown (Král’, Serra and Vena, and Shapira) for monotone linear-invariant properties defined by forbidding solutions to a finite number of equations. But for odd-cycle-freeness whose description involves an infinite number of forbidden equations, a reduction to graph property testing was not previously known. If one could show such a reduction more generally for any linear-invariant property closed under restrictions to subspaces, then it would likely lead to a characterization of the one-sided testable linear-invariant properties, an open problem raised by Sudan.
The second issue we study is whether there is an efficient canonical tester for linear-invariant properties of Boolean functions. A canonical tester for linear-invariant properties operates by picking a random linear subspace and then checking whether the restriction of the input function to the subspace satisfies a fixed property. The question is if, for every linear-invariant property, there is a canonical tester for which there is only a polynomial blow-up from the optimal query complexity. We answer the question affirmatively for odd-cycle-freeness. The general question remains open.


Modern Computer Arithmetic
-
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010
On Sums of Generating Sets in ℤ2n
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 03 August 2012, pp. 916-941
-
- Article
- Export citation
Affine Parikh automata∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 02 August 2012, pp. 511-545
- Print publication:
- October 2012
-
- Article
- Export citation
Normal forms for unary probabilistic automata
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 02 August 2012, pp. 495-510
- Print publication:
- October 2012
-
- Article
- Export citation
Regularity of languages defined by formal series with isolatedcut point∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 02 August 2012, pp. 479-493
- Print publication:
- October 2012
-
- Article
- Export citation
String Assembling Systems
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 02 August 2012, pp. 593-613
- Print publication:
- October 2012
-
- Article
- Export citation
Generating Networks of Splicing Processors
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 30 July 2012, pp. 547-572
- Print publication:
- October 2012
-
- Article
- Export citation
Connectivity for Bridge-Addable Monotone Graph Classes
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 6 / November 2012
- Published online by Cambridge University Press:
- 30 July 2012, pp. 803-815
-
- Article
- Export citation
-
A class
Special Issue: Non-Classical Models of Automata and Applications III (NCMA-2011)
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 4 / October 2012
- Published online by Cambridge University Press:
- 30 July 2012, pp. 459-460
- Print publication:
- October 2012
-
- Article
-
- You have access
- Export citation
Are Stable Instances Easy?
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 5 / September 2012
- Published online by Cambridge University Press:
- 26 July 2012, pp. 643-660
-
- Article
- Export citation
CPC volume 21 issue 5 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 5 / September 2012
- Published online by Cambridge University Press:
- 26 July 2012, pp. b1-b3
-
- Article
-
- You have access
- Export citation
CPC volume 21 issue 5 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 5 / September 2012
- Published online by Cambridge University Press:
- 26 July 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Note on the Smallest Root of the Independence Polynomial
-
- Journal:
- Combinatorics, Probability and Computing / Volume 22 / Issue 1 / January 2013
- Published online by Cambridge University Press:
- 18 July 2012, pp. 1-8
-
- Article
- Export citation
A Graph Polynomial for Independent Sets of Bipartite Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 5 / September 2012
- Published online by Cambridge University Press:
- 10 July 2012, pp. 695-714
-
- Article
- Export citation
