Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry

A Computational Introduction to Number Theory and Algebra
-
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2005

Computational Complexity
- A Conceptual Perspective
-
- Published online:
- 05 June 2012
- Print publication:
- 28 April 2008

Mathematical Theory of Domains
-
- Published online:
- 05 June 2012
- Print publication:
- 22 September 1994

Quantum Computer Science
- An Introduction
-
- Published online:
- 05 June 2012
- Print publication:
- 30 August 2007

Iterative Methods in Combinatorial Optimization
-
- Published online:
- 05 June 2012
- Print publication:
- 18 April 2011

Algorithmic Geometry
-
- Published online:
- 05 June 2012
- Print publication:
- 05 March 1998

Probability and Computing
- Randomized Algorithms and Probabilistic Analysis
-
- Published online:
- 05 June 2012
- Print publication:
- 31 January 2005
-
- Book
- Export citation

Computational Complexity
- A Modern Approach
-
- Published online:
- 05 June 2012
- Print publication:
- 20 April 2009

Enumerative Combinatorics
-
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011

Computational Geometry in C
-
- Published online:
- 05 June 2012
- Print publication:
- 13 October 1998
On the decidability of semigroup freeness∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 29 May 2012, pp. 355-399
- Print publication:
- July 2012
-
- Article
- Export citation
Perfect Graphs of Fixed Density: Counting and Homogeneous Sets
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 5 / September 2012
- Published online by Cambridge University Press:
- 14 May 2012, pp. 661-682
-
- Article
- Export citation
-
For c ∈ (0,1) let
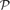

We show that
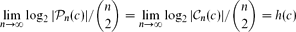 with
with 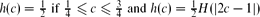
Further, we use this result to deduce that almost all graphs in
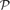

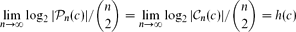
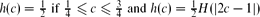
Getting a Directed Hamilton Cycle Two Times Faster
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 5 / September 2012
- Published online by Cambridge University Press:
- 04 May 2012, pp. 773-801
-
- Article
- Export citation
Strong Convergence of Partial Match Queries in Random Quadtrees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 5 / September 2012
- Published online by Cambridge University Press:
- 27 April 2012, pp. 683-694
-
- Article
- Export citation
Unit Distances in Three Dimensions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 25 April 2012, pp. 597-610
-
- Article
- Export citation
Distance Preserving Ramsey Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 23 April 2012, pp. 554-581
-
- Article
- Export citation
k-Sums in Abelian Groups
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 23 April 2012, pp. 582-596
-
- Article
- Export citation
Conflict-Free Colourings of Uniform Hypergraphs With Few Edges
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 20 April 2012, pp. 611-622
-
- Article
- Export citation
-
A colouring of the vertices of a hypergraph
CPC volume 21 issue 3 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 3 / May 2012
- Published online by Cambridge University Press:
- 12 April 2012, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Some Properties of Lower Level-Sets of Convolutions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 12 April 2012, pp. 515-530
-
- Article
- Export citation
