Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Compressions and Probably Intersecting Families
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 02 February 2012, pp. 301-313
-
- Article
- Export citation
-
A family
Standard compression techniques appear inadequate to solve the problem as they do not preserve intersection properties of subfamilies. Instead, our main tool is a novel compression method, together with a way of ‘compressing subfamilies’, which may be of independent interest.
Contents
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp vii-viii
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp i-vi
-
- Chapter
- Export citation
6 - Creating Analysis-Friendly Data
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 181-214
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 1-16
-
- Chapter
- Export citation
4 - Tuning Algorithms, Tuning Code
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 98-151
-
- Chapter
- Export citation
Preface
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp ix-x
-
- Chapter
- Export citation
3 - What to Measure
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 50-97
-
- Chapter
- Export citation
2 - A Plan of Attack
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 17-49
-
- Chapter
- Export citation
7 - Data Analysis
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 215-256
-
- Chapter
- Export citation
5 - The Toolbox
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 152-180
-
- Chapter
- Export citation
Index
-
- Book:
- A Guide to Experimental Algorithmics
- Published online:
- 05 February 2012
- Print publication:
- 30 January 2012, pp 257-261
-
- Chapter
- Export citation
Cliques in Graphs With Bounded Minimum Degree
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 3 / May 2012
- Published online by Cambridge University Press:
- 26 January 2012, pp. 457-482
-
- Article
- Export citation
Limit Theorems for Subtree Size Profiles of Increasing Trees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 3 / May 2012
- Published online by Cambridge University Press:
- 25 January 2012, pp. 412-441
-
- Article
- Export citation
The Size of a Hypergraph and its Matching Number
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 3 / May 2012
- Published online by Cambridge University Press:
- 20 January 2012, pp. 442-450
-
- Article
- Export citation
-
More than forty years ago, Erdős conjectured that for any
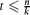 , every k-uniform hypergraph on n vertices without t disjoint edges has at most max
, every k-uniform hypergraph on n vertices without t disjoint edges has at most max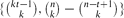 edges. Although this appears to be a basic instance of the hypergraph Turán problem (with a t-edge matching as the excluded hypergraph), progress on this question has remained elusive. In this paper, we verify this conjecture for all
edges. Although this appears to be a basic instance of the hypergraph Turán problem (with a t-edge matching as the excluded hypergraph), progress on this question has remained elusive. In this paper, we verify this conjecture for all 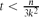 . This improves upon the best previously known range
. This improves upon the best previously known range 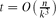 , which dates back to the 1970s.
, which dates back to the 1970s.
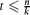 , every
, every 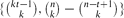 edges. Although this appears to be a basic instance of the hypergraph Turán problem (with a
edges. Although this appears to be a basic instance of the hypergraph Turán problem (with a 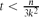 . This improves upon the best previously known range
. This improves upon the best previously known range 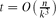 , which dates back to the 1970s.
, which dates back to the 1970s.Order-Invariant Measures on Fixed Causal Sets
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 3 / May 2012
- Published online by Cambridge University Press:
- 19 January 2012, pp. 330-357
-
- Article
- Export citation
On the Banach-Space-Valued Azuma Inequality and Small-Set Isoperimetry of Alon–Roichman Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 18 January 2012, pp. 623-634
-
- Article
- Export citation
Approximating Cayley Diagrams Versus Cayley Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 04 January 2012, pp. 635-641
-
- Article
- Export citation
Special issue dedicated to the thirteenth"Journées Montoises d'Informatique Théorique"
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 1 / January 2012
- Published online by Cambridge University Press:
- 13 February 2012, p. 1
- Print publication:
- January 2012
-
- Article
-
- You have access
- Export citation
Morphisms preserving the set of words coding three intervalexchange∗∗∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 1 / January 2012
- Published online by Cambridge University Press:
- 21 February 2012, pp. 107-122
- Print publication:
- January 2012
-
- Article
- Export citation
