Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
CPC volume 21 issue 3 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 3 / May 2012
- Published online by Cambridge University Press:
- 12 April 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
On the joint 2-adic complexity of binary multisequences∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 06 April 2012, pp. 401-412
- Print publication:
- July 2012
-
- Article
- Export citation
Set Families With a Forbidden Induced Subposet
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 22 March 2012, pp. 496-511
-
- Article
- Export citation
-
For each poset H whose Hasse diagram is a tree of height k, we show that the largest size of a family
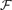
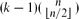 . This extends a result of Bukh [1], which in turn generalizes several known results including Sperner's theorem.
. This extends a result of Bukh [1], which in turn generalizes several known results including Sperner's theorem.
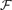
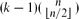 . This extends a result of Bukh [1], which in turn generalizes several known results including Sperner's theorem.
. This extends a result of Bukh [1], which in turn generalizes several known results including Sperner's theorem.Scott's Induced Subdivision Conjecture for Maximal Triangle-Free Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 21 March 2012, pp. 512-514
-
- Article
- Export citation
Monochromatic Cycles in 2-Coloured Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 19 March 2012, pp. 57-87
-
- Article
- Export citation
CPC volume 21 issue 1-2 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 19 March 2012, pp. f1-f2
-
- Article
-
- You have access
- Export citation
CPC volume 21 issue 1-2 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 1-2 / March 2012
- Published online by Cambridge University Press:
- 19 March 2012, pp. b1-b8
-
- Article
-
- You have access
- Export citation
Space Crossing Numbers
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 3 / May 2012
- Published online by Cambridge University Press:
- 16 March 2012, pp. 358-373
-
- Article
- Export citation
Non-Three-Colourable Common Graphs Exist
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 5 / September 2012
- Published online by Cambridge University Press:
- 16 March 2012, pp. 734-742
-
- Article
- Export citation
Measurable Events Indexed by Trees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 3 / May 2012
- Published online by Cambridge University Press:
- 12 March 2012, pp. 374-411
-
- Article
- Export citation
-
A tree T is said to be homogeneous if it is uniquely rooted and there exists an integer b ≥ 2, called the branching number of T, such that every t ∈ T has exactly b immediate successors. We study the behaviour of measurable events in probability spaces indexed by homogeneous trees.
Precisely, we show that for every integer b ≥ 2 and every integer n ≥ 1 there exists an integer q(b,n) with the following property. If T is a homogeneous tree with branching number b and {At:t ∈ T} is a family of measurable events in a probability space (Ω,Σ,μ) satisfying μ(At)≥ϵ>0 for every t ∈ T, then for every 0<θ<ϵ there exists a strong subtree S of T of infinite height, such that for every finite subset F of S of cardinality n ≥ 1 we have
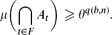 In fact, we can take q(b,n)= ((2b−1)2n−1−1)·(2b−2)−1. A finite version of this result is also obtained.
In fact, we can take q(b,n)= ((2b−1)2n−1−1)·(2b−2)−1. A finite version of this result is also obtained.
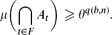
Equivalences and Congruences on Infinite Conway Games∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 02 March 2012, pp. 231-259
- Print publication:
- April 2012
-
- Article
- Export citation
The Density Turán Problem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 29 February 2012, pp. 531-553
-
- Article
- Export citation
-
Let H be a graph on n vertices and let the blow-up graph G[H] be defined as follows. We replace each vertex vi of H by a cluster Ai and connect some pairs of vertices of Ai and Aj if (vi,vj) is an edge of the graph H. As usual, we define the edge density between Ai and Aj as
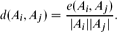 We study the following problem. Given densities γij for each edge (i,j) ∈ E(H), one has to decide whether there exists a blow-up graph G[H], with edge densities at least γij, such that one cannot choose a vertex from each cluster, so that the obtained graph is isomorphic to H, i.e., no H appears as a transversal in G[H]. We call dcrit(H) the maximal value for which there exists a blow-up graph G[H] with edge densities d(Ai,Aj)=dcrit(H) ((vi,vj) ∈ E(H)) not containing H in the above sense. Our main goal is to determine the critical edge density and to characterize the extremal graphs.
We study the following problem. Given densities γij for each edge (i,j) ∈ E(H), one has to decide whether there exists a blow-up graph G[H], with edge densities at least γij, such that one cannot choose a vertex from each cluster, so that the obtained graph is isomorphic to H, i.e., no H appears as a transversal in G[H]. We call dcrit(H) the maximal value for which there exists a blow-up graph G[H] with edge densities d(Ai,Aj)=dcrit(H) ((vi,vj) ∈ E(H)) not containing H in the above sense. Our main goal is to determine the critical edge density and to characterize the extremal graphs.First, in the case of tree T we give an efficient algorithm to decide whether a given set of edge densities ensures the existence of a transversal T in the blow-up graph. Then we give general bounds on dcrit(H) in terms of the maximal degree. In connection with the extremal structure, the so-called star decomposition is proved to give the best construction for H-transversal-free blow-up graphs for several graph classes. Our approach applies algebraic graph-theoretical, combinatorial and probabilistic tools.
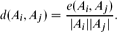
Detachments of Hypergraphs I: The Berge–Johnson Problem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 4 / July 2012
- Published online by Cambridge University Press:
- 27 February 2012, pp. 483-495
-
- Article
- Export citation
-
A detachment of a hypergraph is formed by splitting each vertex into one or more subvertices, and sharing the incident edges arbitrarily among the subvertices. For a given edge-coloured hypergraph
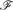
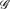
Let
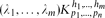 be a hypergraph with vertex partition {V1,. . .,Vn}, |Vi| = pi for 1 ≤ i ≤ n such that there are λi edges of size hi incident with every hi vertices, at most one vertex from each part for 1 ≤ i ≤ m (so no edge is incident with more than one vertex of a part). We use our detachment theorem to show that the obvious necessary conditions for
be a hypergraph with vertex partition {V1,. . .,Vn}, |Vi| = pi for 1 ≤ i ≤ n such that there are λi edges of size hi incident with every hi vertices, at most one vertex from each part for 1 ≤ i ≤ m (so no edge is incident with more than one vertex of a part). We use our detachment theorem to show that the obvious necessary conditions for 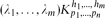 to be expressed as the union
to be expressed as the union
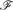
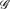
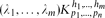 be a hypergraph with vertex partition {
be a hypergraph with vertex partition {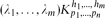 to be expressed as the union
to be expressed as the union A graphical representation of relational formulae withcomplementation∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 27 February 2012, pp. 261-289
- Print publication:
- April 2012
-
- Article
- Export citation
Linear spans of optimal sets of frequency hopping sequences∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 23 February 2012, pp. 343-354
- Print publication:
- July 2012
-
- Article
- Export citation
On the size of transducers for bidirectional decoding of prefixcodes
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 23 February 2012, pp. 315-328
- Print publication:
- April 2012
-
- Article
- Export citation
Easy lambda-terms are not always simple
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 23 February 2012, pp. 291-314
- Print publication:
- April 2012
-
- Article
- Export citation
Foreword ICTCS 2010 special issue
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 21 February 2012, p. 201
- Print publication:
- April 2012
-
- Article
-
- You have access
- Export citation
Formal Methods to Improve Public Administration BusinessProcesses
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 2 / April 2012
- Published online by Cambridge University Press:
- 21 February 2012, pp. 203-229
- Print publication:
- April 2012
-
- Article
- Export citation

Infinite Electrical Networks
-
- Published online:
- 05 February 2012
- Print publication:
- 29 November 1991
