Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Job shop scheduling with unit length tasks
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 3 / July 2012
- Published online by Cambridge University Press:
- 21 December 2011, pp. 329-342
- Print publication:
- July 2012
-
- Article
- Export citation
Frontmatter
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp i-vi
-
- Chapter
- Export citation
4 - Rational Generating Functions
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp 464-570
-
- Chapter
- Export citation
First Edition Numbering
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp 575-580
-
- Chapter
- Export citation
List of Notation (Partial)
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp 581-584
-
- Chapter
- Export citation
Appendix: Graph Theory Terminology
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp 571-574
-
- Chapter
- Export citation
Index
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp 585-626
-
- Chapter
- Export citation
1 - What Is Enumerative Combinatorics?
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp 1-194
-
- Chapter
- Export citation
Contents
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp vii-x
-
- Chapter
- Export citation
3 - Partially Ordered Sets
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp 241-463
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp xiii-xiv
-
- Chapter
- Export citation
2 - Sieve Methods
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp 195-240
-
- Chapter
- Export citation
Preface
-
- Book:
- Enumerative Combinatorics
- Published online:
- 05 June 2012
- Print publication:
- 12 December 2011, pp xi-xii
-
- Chapter
- Export citation
The Turán Number of F3,3
-
- Journal:
- Combinatorics, Probability and Computing / Volume 21 / Issue 3 / May 2012
- Published online by Cambridge University Press:
- 29 November 2011, pp. 451-456
-
- Article
- Export citation
-
Let F3,3 be the 3-graph on 6 vertices, labelled abcxyz, and 10 edges, one of which is abc, and the other 9 of which are all triples that contain 1 vertex from abc and 2 vertices from xyz. We show that for all n ≥ 6, the maximum number of edges in an F3,3-free 3-graph on n vertices is
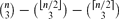 . This sharpens results of Zhou [9] and of the second author and Rödl [7].
. This sharpens results of Zhou [9] and of the second author and Rödl [7].
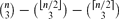 . This sharpens results of Zhou [9] and of the second author and Rödl [7].
. This sharpens results of Zhou [9] and of the second author and Rödl [7].On automatic infinite permutations∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 1 / January 2012
- Published online by Cambridge University Press:
- 23 November 2011, pp. 77-85
- Print publication:
- January 2012
-
- Article
- Export citation
Fixed points of endomorphisms of certain freeproducts
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 1 / January 2012
- Published online by Cambridge University Press:
- 23 November 2011, pp. 165-179
- Print publication:
- January 2012
-
- Article
- Export citation
An aperiodicity problem for multiwords
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 1 / January 2012
- Published online by Cambridge University Press:
- 23 November 2011, pp. 33-50
- Print publication:
- January 2012
-
- Article
- Export citation
Three complexity functions
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 1 / January 2012
- Published online by Cambridge University Press:
- 23 November 2011, pp. 67-76
- Print publication:
- January 2012
-
- Article
- Export citation
On Abelian repetition threshold
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 46 / Issue 1 / January 2012
- Published online by Cambridge University Press:
- 14 November 2011, pp. 147-163
- Print publication:
- January 2012
-
- Article
- Export citation

Domains and Lambda-Calculi
-
- Published online:
- 05 November 2011
- Print publication:
- 02 July 1998
