Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
3 - Algorithms for Solving Parity Games
-
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp 74-98
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp i-iv
-
- Chapter
- Export citation
1 - A Primer on Strategic Games
-
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp 1-37
-
- Chapter
- Export citation
7 - Graph Searching Games
-
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp 213-263
-
- Chapter
- Export citation
Preface
-
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp ix-xii
-
- Chapter
- Export citation
5 - Turn-Based Stochastic Games
-
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp 146-184
-
- Chapter
- Export citation
Index
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp 291-295
-
- Chapter
- Export citation
ICTCS 09Foreword
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 15 March 2011, pp. 1-2
- Print publication:
- January 2011
-
- Article
-
- You have access
- Export citation
Hopcroft's algorithmand tree-like automata
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 15 March 2011, pp. 59-75
- Print publication:
- January 2011
-
- Article
- Export citation
Strategies to scan pictures with automata based on Wang tiles
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 15 March 2011, pp. 163-180
- Print publication:
- January 2011
-
- Article
- Export citation
Consensual languages and matching finite-state computations
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 15 March 2011, pp. 77-97
- Print publication:
- January 2011
-
- Article
- Export citation
An introduction to quantum annealing
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 15 March 2011, pp. 99-116
- Print publication:
- January 2011
-
- Article
- Export citation
The compositional constructionof Markov processes II
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 15 March 2011, pp. 117-142
- Print publication:
- January 2011
-
- Article
- Export citation
Enumerated type semantics for the calculus of looping sequences
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 15 March 2011, pp. 35-58
- Print publication:
- January 2011
-
- Article
- Export citation
Idealized coinductive type systemsfor imperative object-oriented programs
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 15 March 2011, pp. 3-33
- Print publication:
- January 2011
-
- Article
- Export citation
Extending the lambda-calculuswith unbind and rebind
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 15 March 2011, pp. 143-162
- Print publication:
- January 2011
-
- Article
- Export citation
Local Resilience and Hamiltonicity Maker–Breaker Games in Random Regular Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 2 / March 2011
- Published online by Cambridge University Press:
- 16 December 2010, pp. 173-211
-
- Article
- Export citation
-
For an increasing monotone graph property
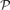
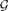
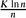 then, with high probability, the local resilience of
then, with high probability, the local resilience of
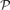
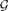
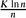 then, with high probability, the local resilience of
then, with high probability, the local resilience of A Lower Bound for the Size of a Minkowski Sum of Dilates
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 2 / March 2011
- Published online by Cambridge University Press:
- 06 December 2010, pp. 249-256
-
- Article
- Export citation
CPC volume 20 issue 1 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 03 December 2010, pp. b1-b2
-
- Article
-
- You have access
- Export citation
CPC volume 20 issue 1 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 03 December 2010, pp. f1-f2
-
- Article
-
- You have access
- Export citation
