Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
The Dual BKR Inequality and Rudich's Conjecture
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 2 / March 2011
- Published online by Cambridge University Press:
- 02 December 2010, pp. 257-266
-
- Article
- Export citation
-
Let
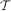
We prove a stronger version: for any independent assignment of the variables (not necessarily the uniform one), if the measure of U(
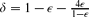 . (A key part of the proof is a correlation-like inequality on events in a finite product probability space that is in some sense dual to Reimer's inequality [11], a.k.a. the BKR inequality [5], or the van den Berg–Kesten conjecture [3].)
. (A key part of the proof is a correlation-like inequality on events in a finite product probability space that is in some sense dual to Reimer's inequality [11], a.k.a. the BKR inequality [5], or the van den Berg–Kesten conjecture [3].)
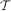
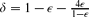 . (A key part of the proof is a correlation-like inequality on events in a finite product probability space that is in some sense dual to Reimer's inequality [11], a.k.a. the BKR inequality [5], or the van den Berg–Kesten conjecture [3].)
. (A key part of the proof is a correlation-like inequality on events in a finite product probability space that is in some sense dual to Reimer's inequality [11], a.k.a. the BKR inequality [5], or the van den Berg–Kesten conjecture [3].)References
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp 191-206
-
- Chapter
- Export citation
3 - Floating-point arithmetic
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp 79-124
-
- Chapter
- Export citation
5 - Implementations and pointers
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp 185-190
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp i-iv
-
- Chapter
- Export citation
Acknowledgements
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp xi-xii
-
- Chapter
- Export citation
Preface
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp ix-x
-
- Chapter
- Export citation
Index
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp 207-221
-
- Chapter
- Export citation
Contents
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp v-viii
-
- Chapter
- Export citation
1 - Integer arithmetic
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp 1-46
-
- Chapter
- Export citation
2 - Modular arithmetic and the FFT
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp 47-78
-
- Chapter
- Export citation
4 - Elementary and special function evaluation
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp 125-184
-
- Chapter
- Export citation
Notation
-
- Book:
- Modern Computer Arithmetic
- Published online:
- 05 August 2012
- Print publication:
- 25 November 2010, pp xiii-xvi
-
- Chapter
- Export citation
On Barycentric Subdivision
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 2 / March 2011
- Published online by Cambridge University Press:
- 24 November 2010, pp. 213-237
-
- Article
- Export citation

Permutation Patterns
-
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010
Diameters in Supercritical Random Graphs Via First Passage Percolation
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 05 October 2010, pp. 729-751
-
- Article
- Export citation
-
We study the diameter of
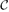
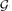
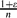 where ε3n → ∞ and ε = o(1). This parameter was extensively studied for fixed ε > 0, yet results for ε = o(1) outside the critical window were only obtained very recently. Prior to this work, Riordan and Wormald gave precise estimates on the diameter; however, these did not cover the entire supercritical regime (namely, when ε3n → ∞ arbitrarily slowly). Łuczak and Seierstad estimated its order throughout this regime, yet their upper and lower bounds differed by a factor of
where ε3n → ∞ and ε = o(1). This parameter was extensively studied for fixed ε > 0, yet results for ε = o(1) outside the critical window were only obtained very recently. Prior to this work, Riordan and Wormald gave precise estimates on the diameter; however, these did not cover the entire supercritical regime (namely, when ε3n → ∞ arbitrarily slowly). Łuczak and Seierstad estimated its order throughout this regime, yet their upper and lower bounds differed by a factor of 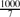 .
.We show that throughout the emerging supercritical phase, i.e., for any ε = o(1) with ε3n → ∞, the diameter of
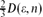 , and the maximal distance in
, and the maximal distance in 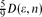 .
.
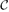
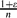 where ε
where ε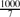 .
.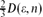 , and the maximal distance in
, and the maximal distance in 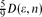 .
.CPC volume 19 issue 5-6 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 05 October 2010, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Introduction
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 05 October 2010, p. 641
-
- Article
- Export citation
The Diameter of Sparse Random Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 05 October 2010, pp. 835-926
-
- Article
- Export citation
On Random Betweenness Constraints
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 05 October 2010, pp. 775-790
-
- Article
- Export citation
