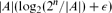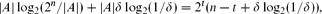Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
5 - Matroids
-
- Book:
- Iterative Methods in Combinatorial Optimization
- Published online:
- 05 June 2012
- Print publication:
- 18 April 2011, pp 65-87
-
- Chapter
- Export citation
Contents
-
- Book:
- Iterative Methods in Combinatorial Optimization
- Published online:
- 05 June 2012
- Print publication:
- 18 April 2011, pp v-viii
-
- Chapter
- Export citation
Index
-
- Book:
- Iterative Methods in Combinatorial Optimization
- Published online:
- 05 June 2012
- Print publication:
- 18 April 2011, pp 241-242
-
- Chapter
- Export citation
2 - Preliminaries
-
- Book:
- Iterative Methods in Combinatorial Optimization
- Published online:
- 05 June 2012
- Print publication:
- 18 April 2011, pp 12-27
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Iterative Methods in Combinatorial Optimization
- Published online:
- 05 June 2012
- Print publication:
- 18 April 2011, pp 233-240
-
- Chapter
- Export citation
Minors in Graphs with High Chromatic Number
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 13 April 2011, pp. 513-518
-
- Article
- Export citation

Analytic Combinatorics
-
- Published online:
- 11 April 2011
- Print publication:
- 15 January 2009
Many Random Walks Are Faster Than One†
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 07 April 2011, pp. 481-502
-
- Article
- Export citation
Incidences in Three Dimensions and Distinct Distances in the Plane†
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 04 April 2011, pp. 571-608
-
- Article
- Export citation
Normalization of edit sequencesfor text synchronization
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 2 / April 2011
- Published online by Cambridge University Press:
- 18 April 2011, pp. 235-248
- Print publication:
- April 2011
-
- Article
- Export citation
Unique decipherability in the additive monoid of sets of numbers
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 2 / April 2011
- Published online by Cambridge University Press:
- 13 May 2011, pp. 225-234
- Print publication:
- April 2011
-
- Article
- Export citation
-
Sets of integers form a monoid, where the product of two sets Aand B is defined as the set containing a+b for all $a\in A$
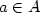 and$b\in B$
and$b\in B$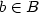 . We give a characterization of when a family of finitesets is a code in this monoid, that is when the sets do not satisfyany nontrivial relation. We also extend this result for someinfinite sets, including all infinite rational sets.
. We give a characterization of when a family of finitesets is a code in this monoid, that is when the sets do not satisfyany nontrivial relation. We also extend this result for someinfinite sets, including all infinite rational sets.
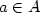
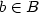
Advice Complexity and Barely Random Algorithms
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 2 / April 2011
- Published online by Cambridge University Press:
- 24 June 2011, pp. 249-267
- Print publication:
- April 2011
-
- Article
- Export citation
On the parameterized complexity of approximate counting
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 2 / April 2011
- Published online by Cambridge University Press:
- 18 April 2011, pp. 197-223
- Print publication:
- April 2011
-
- Article
- Export citation
-
In this paper we study the parameterized complexity of approximating theparameterized counting problems contained in the class $\#W[P]$
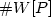 ,the parameterized analogue of $\#P$
,the parameterized analogue of $\#P$ . We prove a parameterized analogue of afamous theorem of Stockmeyer claiming that approximate counting belongs tothe second level of the polynomial hierarchy.
. We prove a parameterized analogue of afamous theorem of Stockmeyer claiming that approximate counting belongs tothe second level of the polynomial hierarchy.
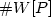

CPC volume 20 issue 3 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 23 March 2011, pp. f1-f2
-
- Article
-
- You have access
- Export citation
CPC volume 20 issue 3 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 23 March 2011, pp. b1-b2
-
- Article
-
- You have access
- Export citation
The Tutte Polynomial Characterizes Simple Outerplanar Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 09 March 2011, pp. 609-616
-
- Article
- Export citation
A Graph-Grabbing Game
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 09 March 2011, pp. 623-629
-
- Article
- Export citation
An improved derandomized approximation algorithmfor the max-controlledset problem
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 2 / April 2011
- Published online by Cambridge University Press:
- 28 February 2011, pp. 181-196
- Print publication:
- April 2011
-
- Article
- Export citation
-
A vertex i of a graph G = (V,E) is said to be controlled by $M \subseteq V$
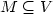 if the majority of the elements ofthe neighborhood of i (including itself) belong to M. The setM is a monopoly in G if every vertex $i\in V$
if the majority of the elements ofthe neighborhood of i (including itself) belong to M. The setM is a monopoly in G if every vertex $i\in V$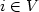 iscontrolled by M. Given a set $M \subseteq V$ and two graphsG1 = ($V,E_1$
iscontrolled by M. Given a set $M \subseteq V$ and two graphsG1 = ($V,E_1$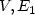 ) and G2 = ($V,E_2$
) and G2 = ($V,E_2$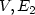 ) where $E_1\subseteq E_2$
) where $E_1\subseteq E_2$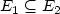 , themonopoly verification problem (mvp) consists of decidingwhether there exists a sandwich graph G = (V,E) (i.e., a graphwhere $E_1\subseteq E\subseteq E_2$
, themonopoly verification problem (mvp) consists of decidingwhether there exists a sandwich graph G = (V,E) (i.e., a graphwhere $E_1\subseteq E\subseteq E_2$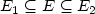 ) such that M is a monopolyin G = (V,E). If the answer to the mvp is No, we thenconsider the max-controlled set problem (mcsp), whoseobjective is to find a sandwich graph G = (V,E) such that thenumber of vertices of G controlled by M is maximized. The mvp can be solved in polynomial time; the mcsp, however, isNP-hard. In this work, we present a deterministic polynomial timeapproximation algorithm for the mcsp with ratio$\frac{1}{2}$
) such that M is a monopolyin G = (V,E). If the answer to the mvp is No, we thenconsider the max-controlled set problem (mcsp), whoseobjective is to find a sandwich graph G = (V,E) such that thenumber of vertices of G controlled by M is maximized. The mvp can be solved in polynomial time; the mcsp, however, isNP-hard. In this work, we present a deterministic polynomial timeapproximation algorithm for the mcsp with ratio$\frac{1}{2}$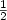 + $\frac{1+\sqrt{n}}{2n-2}$
+ $\frac{1+\sqrt{n}}{2n-2}$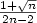 , where n=|V|>4. (Thecase $n\leq4$
, where n=|V|>4. (Thecase $n\leq4$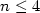 is solved exactly by considering the parameterizedversion of the mcsp.) The algorithm is obtained through theuse of randomized rounding and derandomization techniques based onthe method of conditional expectations. Additionally, we show howto improve this ratio if good estimates of expectation are obtained in advance.
is solved exactly by considering the parameterizedversion of the mcsp.) The algorithm is obtained through theuse of randomized rounding and derandomization techniques based onthe method of conditional expectations. Additionally, we show howto improve this ratio if good estimates of expectation are obtained in advance.
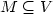
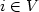
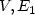
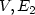
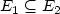
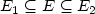
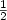
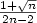
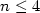
Negative Dependence and Srinivasan's Sampling Process
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 22 February 2011, pp. 347-361
-
- Article
- Export citation
Almost Isoperimetric Subsets of the Discrete Cube
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 17 February 2011, pp. 363-380
-
- Article
- Export citation
-
We show that a set A ⊂ {0, 1}n with edge-boundary of size at most
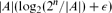 can be made into a subcube by at most (2ε/log2(1/ε))|A| additions and deletions, provided ε is less than an absolute constant.
can be made into a subcube by at most (2ε/log2(1/ε))|A| additions and deletions, provided ε is less than an absolute constant.We deduce that if A ⊂ {0, 1}n has size 2t for some t ∈ ℕ, and cannot be made into a subcube by fewer than δ|A| additions and deletions, then its edge-boundary has size at least
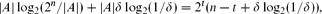 provided δ is less than an absolute constant. This is sharp whenever δ = 1/2j for some j ∈ {1, 2, . . ., t}.
provided δ is less than an absolute constant. This is sharp whenever δ = 1/2j for some j ∈ {1, 2, . . ., t}.