Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
The Evolution of the Cover Time
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 15 February 2011, pp. 331-345
-
- Article
- Export citation
The Blind Passenger and the Assignment Problem
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 14 February 2011, pp. 467-480
-
- Article
- Export citation
Covering Complete r-Graphs with Spanning Complete r-Partite r-Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 09 February 2011, pp. 519-527
-
- Article
- Export citation
-
An r-cut of the complete r-uniform hypergraph Krn is obtained by partitioning its vertex set into r parts and taking all edges that meet every part in exactly one vertex. In other words it is the edge set of a spanning complete r-partite subhypergraph of Krn. An r-cut cover is a collection of r-cuts such that each edge of Krn is in at least one of the cuts. While in the graph case r = 2 any 2-cut cover on average covers each edge at least 2-o(1) times, when r is odd we exhibit an r-cut cover in which each edge is covered exactly once. When r is even no such decomposition can exist, but we can bound the average number of times an edge is cut in an r-cut cover between
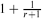 and
and 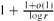 . The upper bound construction can be reformulated in terms of a natural polyhedral problem or as a probability problem, and we solve the latter asymptotically.
. The upper bound construction can be reformulated in terms of a natural polyhedral problem or as a probability problem, and we solve the latter asymptotically.
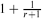 and
and 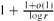 . The upper bound construction can be reformulated in terms of a natural polyhedral problem or as a probability problem, and we solve the latter asymptotically.
. The upper bound construction can be reformulated in terms of a natural polyhedral problem or as a probability problem, and we solve the latter asymptotically.Szemerédi's Regularity Lemma for Matrices and Sparse Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 03 February 2011, pp. 455-466
-
- Article
- Export citation
Asymptotics for First-Passage Times on Delaunay Triangulations
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 03 February 2011, pp. 435-453
-
- Article
- Export citation

Algorithmic Game Theory
-
- Published online:
- 31 January 2011
- Print publication:
- 24 September 2007
CPC volume 20 issue 2 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 2 / March 2011
- Published online by Cambridge University Press:
- 28 January 2011, pp. f1-f2
-
- Article
-
- You have access
- Export citation
CPC volume 20 issue 2 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 2 / March 2011
- Published online by Cambridge University Press:
- 28 January 2011, pp. b1-b2
-
- Article
-
- You have access
- Export citation
Non-Degenerate Spheres in Three Dimensions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 28 January 2011, pp. 503-512
-
- Article
- Export citation
Modular Orientations of Random and Quasi-Random Regular Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 27 January 2011, pp. 321-329
-
- Article
- Export citation
Subgraphs of Dense Random Graphs with Specified Degrees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 27 January 2011, pp. 413-433
-
- Article
- Export citation

Advanced Data Structures
-
- Published online:
- 25 January 2011
- Print publication:
- 08 September 2008

Epidemics and Rumours in Complex Networks
-
- Published online:
- 25 January 2011
- Print publication:
- 03 December 2009
3-Connected Cores In Random Planar Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 3 / May 2011
- Published online by Cambridge University Press:
- 24 January 2011, pp. 381-412
-
- Article
- Export citation
-
The study of the structural properties of large random planar graphs has become in recent years a field of intense research in computer science and discrete mathematics. Nowadays, a random planar graph is an important and challenging model for evaluating methods that are developed to study properties of random graphs from classes with structural side constraints.
In this paper we focus on the structure of random 2-connected planar graphs regarding the sizes of their 3-connected building blocks, which we call cores. In fact, we prove a general theorem regarding random biconnected graphs from various classes. If Bn is a graph drawn uniformly at random from a suitable class

(i) either there is a unique giant core in Bn, that is, there is a 0 < c = c(
(ii) or all cores of Bn contain O(logn) vertices.

8 - Beyond Nash Equilibrium: Solution Concepts for the 21st Century
-
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp 264-290
-
- Chapter
- Export citation
Contents
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp v-vii
-
- Chapter
- Export citation
2 - Infinite Games and Automata Theory
-
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp 38-73
-
- Chapter
- Export citation
List of contributors
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp viii-viii
-
- Chapter
- Export citation
6 - Games with Imperfect Information: Theory and Algorithms
-
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp 185-212
-
- Chapter
- Export citation
4 - Back and Forth Between Logic and Games
-
-
- Book:
- Lectures in Game Theory for Computer Scientists
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011, pp 99-145
-
- Chapter
- Export citation
