Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
CPC volume 19 issue 5-6 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 05 October 2010, pp. b1-b4
-
- Article
-
- You have access
- Export citation
Sturmian jungle (or garden?)on multiliteral alphabets
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 4 / October 2010
- Published online by Cambridge University Press:
- 28 February 2011, pp. 443-470
- Print publication:
- October 2010
-
- Article
- Export citation
Classes of two-dimensional languagesand recognizability conditions
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 4 / October 2010
- Published online by Cambridge University Press:
- 28 February 2011, pp. 471-488
- Print publication:
- October 2010
-
- Article
- Export citation
Quantum coherent spaces and linear logic
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 4 / October 2010
- Published online by Cambridge University Press:
- 28 October 2010, pp. 419-441
- Print publication:
- October 2010
-
- Article
- Export citation
Translation from classical two-way automata to pebble two-way automata
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 4 / October 2010
- Published online by Cambridge University Press:
- 28 February 2011, pp. 507-523
- Print publication:
- October 2010
-
- Article
- Export citation
-
We study the relation between the standard two-way automata andmore powerful devices, namely, two-way finite automata equippedwith some $\ell$
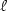 additional “pebbles” that are movable alongthe input tape, but their use is restricted (nested) ina stack-like fashion. Similarly as in the case of the classicaltwo-way machines, it is not known whether there existsa polynomial trade-off, in the number of states, between thenondeterministic and deterministic two-way automata with $\ell$ nested pebbles. However, we show that these two machine modelsare not independent: if there exists a polynomial trade-off forthe classical two-way automata, then, for each $\ell$ ≥ 0,there must also exist a polynomial trade-off for the two-wayautomata with $\ell$ nested pebbles. Thus, we have an upwardcollapse (or a downward separation) from the classical two-wayautomata to more powerful pebble automata, still staying withinthe class of regular languages. The same upward collapse holdsfor complementation of nondeterministic two-way machines. These results are obtained by showing that each pebble machinecan be, by using suitable inputs, simulated by a classicaltwo-way automaton (and vice versa), with only a linear number ofstates, despite the existing exponential blow-up between theclassical and pebble two-way machines.
additional “pebbles” that are movable alongthe input tape, but their use is restricted (nested) ina stack-like fashion. Similarly as in the case of the classicaltwo-way machines, it is not known whether there existsa polynomial trade-off, in the number of states, between thenondeterministic and deterministic two-way automata with $\ell$ nested pebbles. However, we show that these two machine modelsare not independent: if there exists a polynomial trade-off forthe classical two-way automata, then, for each $\ell$ ≥ 0,there must also exist a polynomial trade-off for the two-wayautomata with $\ell$ nested pebbles. Thus, we have an upwardcollapse (or a downward separation) from the classical two-wayautomata to more powerful pebble automata, still staying withinthe class of regular languages. The same upward collapse holdsfor complementation of nondeterministic two-way machines. These results are obtained by showing that each pebble machinecan be, by using suitable inputs, simulated by a classicaltwo-way automaton (and vice versa), with only a linear number ofstates, despite the existing exponential blow-up between theclassical and pebble two-way machines.
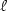
The code problem for directed figures
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 4 / October 2010
- Published online by Cambridge University Press:
- 28 February 2011, pp. 489-506
- Print publication:
- October 2010
-
- Article
- Export citation
A CAT algorithm for the exhaustive generation of ice piles
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 4 / October 2010
- Published online by Cambridge University Press:
- 28 February 2011, pp. 525-543
- Print publication:
- October 2010
-
- Article
- Export citation
-
We present a CAT (constant amortized time) algorithm for generating those partitions of n that are in the ice pile model $\mbox{IPM}_k$
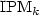 (n),a generalization of the sand pile model $\mbox{SPM}$
(n),a generalization of the sand pile model $\mbox{SPM}$ 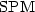 (n).More precisely, for any fixed integer k, we show thatthe negative lexicographic ordering naturally identifies a tree structure on the lattice $\mbox{IPM}_k$ (n):this lets us design an algorithm which generates all the ice piles of $\mbox{IPM}_k$ (n)in amortized timeO(1)and in spaceO( $\sqrt n$
(n).More precisely, for any fixed integer k, we show thatthe negative lexicographic ordering naturally identifies a tree structure on the lattice $\mbox{IPM}_k$ (n):this lets us design an algorithm which generates all the ice piles of $\mbox{IPM}_k$ (n)in amortized timeO(1)and in spaceO( $\sqrt n$ 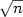 ).
).
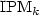
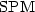
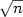
Graphs, Links, and Duality on Surfaces
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 2 / March 2011
- Published online by Cambridge University Press:
- 29 September 2010, pp. 267-287
-
- Article
- Export citation
Period Lengths for Iterated Functions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 2 / March 2011
- Published online by Cambridge University Press:
- 16 September 2010, pp. 289-298
-
- Article
- Export citation
-
Let Ωn be the nn-element set consisting of all functions that have {1, 2, 3, . . ., n} as both domain and codomain. Let T(f) be the order of f, i.e., the period of the sequence f, f(2), f(3), f(4) . . . of compositional iterates. A closely related number, B(f) = the product of the lengths of the cycles of f, has previously been used as an approximation for T. This paper proves that the average values of these two quantities are quite different. The expected value of T is
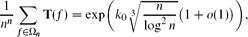 where k0 is a complicated but explicitly defined constant that is approximately 3.36. The expected value of B is much larger:
where k0 is a complicated but explicitly defined constant that is approximately 3.36. The expected value of B is much larger: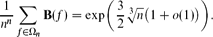
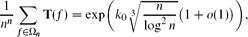
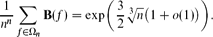
15 - Arbitrarily high order of convergence of the worst-case error
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp 465-508
-
- Chapter
- Export citation
14 - The decay of the Walsh coefficients of smooth functions
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp 434-464
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp i-iv
-
- Chapter
- Export citation
Dedication
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp v-vi
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp 1-15
-
- Chapter
- Export citation
11 - Cyclic digital nets and hyperplane nets
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp 344-362
-
- Chapter
- Export citation
Index
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp 597-600
-
- Chapter
- Export citation
12 - Multivariate integration in weighted Sobolev spaces
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp 363-394
-
- Chapter
- Export citation
References
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp 583-596
-
- Chapter
- Export citation
9 - Propagation rules for digital nets
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp 285-297
-
- Chapter
- Export citation
3 - Geometric discrepancy
-
- Book:
- Digital Nets and Sequences
- Published online:
- 05 July 2014
- Print publication:
- 09 September 2010, pp 46-107
-
- Chapter
- Export citation
