Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Overview
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp xvii-xx
-
- Chapter
- Export citation
Notations and Conventions
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp xxv-xxvi
-
- Chapter
- Export citation
4 - NP-Completeness
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp 96-141
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp i-vi
-
- Chapter
- Export citation
Contents
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp vii-x
-
- Chapter
- Export citation
Main Definitions and Results
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp xxvii-xxx
-
- Chapter
- Export citation
Epilogue: A Brief Overview of Complexity Theory
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp 169-176
-
- Chapter
- Export citation
3 - Polynomial-time Reductions
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp 74-95
-
- Chapter
- Export citation
5 - Three Relatively Advanced Topics
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp 142-164
-
- Chapter
- Export citation
Bibliography
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp 181-182
-
- Chapter
- Export citation
Appendix - Some Computational Problems
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp 177-180
-
- Chapter
- Export citation
To the Teacher
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp xxi-xxiv
-
- Chapter
- Export citation
1 - Computational Tasks and Models
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp 1-47
-
- Chapter
- Export citation
2 - The P versus NP Question
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp 48-73
-
- Chapter
- Export citation
Preface
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp xiii-xvi
-
- Chapter
- Export citation
Index
-
- Book:
- P, NP, and NP-Completeness
- Published online:
- 05 June 2012
- Print publication:
- 16 August 2010, pp 183-184
-
- Chapter
- Export citation
Bootstrap Percolation in High Dimensions
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 12 August 2010, pp. 643-692
-
- Article
- Export citation
-
In r-neighbour bootstrap percolation on a graph G, a set of initially infected vertices A ⊂ V(G) is chosen independently at random, with density p, and new vertices are subsequently infected if they have at least r infected neighbours. The set A is said to percolate if eventually all vertices are infected. Our aim is to understand this process on the grid, [n]d, for arbitrary functions n = n(t), d = d(t) and r = r(t), as t → ∞. The main question is to determine the critical probability pc([n]d, r) at which percolation becomes likely, and to give bounds on the size of the critical window. In this paper we study this problem when r = 2, for all functions n and d satisfying d ≫ log n.
The bootstrap process has been extensively studied on [n]d when d is a fixed constant and 2 ⩽ r ⩽ d, and in these cases pc([n]d, r) has recently been determined up to a factor of 1 + o(1) as n → ∞. At the other end of the scale, Balogh and Bollobás determined pc([2]d, 2) up to a constant factor, and Balogh, Bollobás and Morris determined pc([n]d, d) asymptotically if d ≥ (log log n)2+ϵ, and gave much sharper bounds for the hypercube.
Here we prove the following result. Let λ be the smallest positive root of the equation
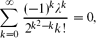 so λ ≈ 1.166. Then
so λ ≈ 1.166. Then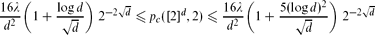 if d is sufficiently large, and moreover
if d is sufficiently large, and moreover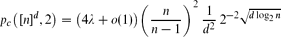 as d → ∞, for every function n = n(d) with d ≫ log n.
as d → ∞, for every function n = n(d) with d ≫ log n.
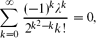
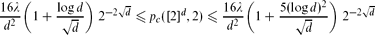
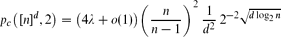

From Semantics to Computer Science
- Essays in Honour of Gilles Kahn
-
- Published online:
- 06 August 2010
- Print publication:
- 24 September 2009

Algebraic Set Theory
-
- Published online:
- 04 August 2010
- Print publication:
- 14 September 1995
A Bijective Proof of a Theorem of Knuth
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 21 July 2010, pp. 11-25
-
- Article
- Export citation
-
The line graph