Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
The 3-Colour Ramsey Number of a 3-Uniform Berge Cycle
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 02 July 2010, pp. 53-71
-
- Article
- Export citation
-
The asymptotics of 2-colour Ramsey numbers of loose and tight cycles in 3-uniform hypergraphs were recently determined [16, 17]. We address the same problem for Berge cycles and for 3 colours. Our main result is that the 3-colour Ramsey number of a 3-uniform Berge cycle of length n is asymptotic to
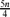 . The result is proved with the Regularity Lemma via the existence of a monochromatic connected matching covering asymptotically 4n/5 vertices in the multicoloured 2-shadow graph induced by the colouring of Kn(3).
. The result is proved with the Regularity Lemma via the existence of a monochromatic connected matching covering asymptotically 4n/5 vertices in the multicoloured 2-shadow graph induced by the colouring of Kn(3).
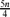 . The result is proved with the Regularity Lemma via the existence of a monochromatic connected matching covering asymptotically 4
. The result is proved with the Regularity Lemma via the existence of a monochromatic connected matching covering asymptotically 4A Threshold Phenomenon for Random Independent Sets in the Discrete Hypercube
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 02 July 2010, pp. 27-51
-
- Article
- Export citation
-
Let I be an independent set drawn from the discrete d-dimensional hypercube Qd = {0, 1}d according to the hard-core distribution with parameter λ > 0 (that is, the distribution in which each independent set I is chosen with probability proportional to λ|I|). We show a sharp transition around λ = 1 in the appearance of I: for λ > 1, min{|I ∩ Ɛ|, |I ∩
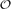
A key step in the proof is an estimation of Zλ(Qd), the sum over independent sets in Qd with each set I given weight λ|I| (a.k.a. the hard-core partition function). We obtain the asymptotics of Zλ(Qd) for
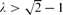 , and nearly matching upper and lower bounds for
, and nearly matching upper and lower bounds for 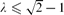 , extending work of Korshunov and Sapozhenko. These bounds allow us to read off some very specific information about the structure of an independent set drawn according to the hard-core distribution.
, extending work of Korshunov and Sapozhenko. These bounds allow us to read off some very specific information about the structure of an independent set drawn according to the hard-core distribution.We also derive a long-range influence result. For all fixed λ > 0, if I is chosen from the independent sets of Qd according to the hard-core distribution with parameter λ, conditioned on a particular v ∈ Ɛ being in I, then the probability that another vertex w is in I is o(1) for w ∈
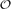
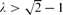 , and nearly matching upper and lower bounds for
, and nearly matching upper and lower bounds for 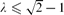 , extending work of Korshunov and Sapozhenko. These bounds allow us to read off some very specific information about the structure of an independent set drawn according to the hard-core distribution.
, extending work of Korshunov and Sapozhenko. These bounds allow us to read off some very specific information about the structure of an independent set drawn according to the hard-core distribution.Corrigendum to our paper:How Expressions Can Code for Automata
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 3 / July 2010
- Published online by Cambridge University Press:
- 28 July 2010, pp. 339-361
- Print publication:
- July 2010
-
- Article
- Export citation
Balances and Abelian Complexityof a Certain Class of Infinite Ternary Words
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 3 / July 2010
- Published online by Cambridge University Press:
- 20 July 2010, pp. 313-337
- Print publication:
- July 2010
-
- Article
- Export citation
-
A word u defined over an alphabet $\mathcal A$
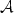 is c-balanced (c∈ $\mathbb N$
is c-balanced (c∈ $\mathbb N$ 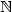 ) if for all pairs of factors v, w of u of the same lengthand for all letters a∈ $\mathcal A$ , the difference between the number of letters a in v and w is less or equal to c. In this paper we consider a ternary alphabet $\mathcal A$ = {L, S, M} and a class of substitutions $\varphi_p$
) if for all pairs of factors v, w of u of the same lengthand for all letters a∈ $\mathcal A$ , the difference between the number of letters a in v and w is less or equal to c. In this paper we consider a ternary alphabet $\mathcal A$ = {L, S, M} and a class of substitutions $\varphi_p$ 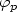 defined by $\varphi_p$ (L) = LpS, $\varphi_p$ (S) = M, $\varphi_p$ (M) = Lp–1S where p> 1.We prove that the fixed point of $\varphi_p$ , formally written as $\varphi_p^\infty$
defined by $\varphi_p$ (L) = LpS, $\varphi_p$ (S) = M, $\varphi_p$ (M) = Lp–1S where p> 1.We prove that the fixed point of $\varphi_p$ , formally written as $\varphi_p^\infty$ 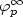 (L), is 3-balanced and that its Abelian complexity is bounded above by the value 7, regardless of the value of p. We also show that both these bounds are optimal, i.e. they cannot be improved.
(L), is 3-balanced and that its Abelian complexity is bounded above by the value 7, regardless of the value of p. We also show that both these bounds are optimal, i.e. they cannot be improved.
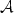
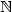
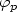
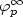
The Uniform Minimum-Ones 2SAT Problemand its Application to Haplotype Classification
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 3 / July 2010
- Published online by Cambridge University Press:
- 28 July 2010, pp. 363-377
- Print publication:
- July 2010
-
- Article
- Export citation
-
Analyzing genomic data for finding those gene variations which are responsible for hereditary diseases is one of the great challenges in modern bioinformatics. In many living beings (including the human), every gene is present in two copies, inherited from the two parents, the so-called haplotypes. In this paper, we propose a simple combinatorial model for classifying the set of haplotypes in a population according to their responsibility for a certain genetic disease. This model is based on the minimum-ones 2SAT problem with uniform clauses.The minimum-ones 2SAT problem asks for a satisfying assignment to a satisfiable formula in 2CNF which sets a minimum number of variables to true. This problem is well-known to be $\mathcal{NP}$
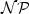 -hard, even in the case where all clauses are uniform, i.e., do not contain a positive and a negative literal. We analyze the approximability and present the first non-trivial exact algorithm for the uniform minimum-ones 2SAT problem with a running time of $\mathcal{O}$
-hard, even in the case where all clauses are uniform, i.e., do not contain a positive and a negative literal. We analyze the approximability and present the first non-trivial exact algorithm for the uniform minimum-ones 2SAT problem with a running time of $\mathcal{O}$  (1.21061n ) on a 2SAT formula with n variables. We also show that the problem is fixed-parameter tractable by showing that our algorithm can be adapted to verify in $\mathcal{O}^*$
(1.21061n ) on a 2SAT formula with n variables. We also show that the problem is fixed-parameter tractable by showing that our algorithm can be adapted to verify in $\mathcal{O}^*$ 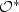 (2k ) time whether an assignment with at most k true variables exists.
(2k ) time whether an assignment with at most k true variables exists.

Function operators spanning the arithmetical and the polynomial hierarchy
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 44 / Issue 3 / July 2010
- Published online by Cambridge University Press:
- 05 October 2010, pp. 379-418
- Print publication:
- July 2010
-
- Article
- Export citation
-
A modified version of the classical µ -operator as well as thefirst value operator and the operator of inverting unaryfunctions, applied in combination with the composition offunctions and starting from the primitive recursive functions,generate all arithmetically representable functions. Moreover, thenesting levels of these operators are closely related to thestratification of the arithmetical hierarchy. The same is shownfor some further function operators known from computability and complexitytheory. The close relationships between nesting levels of operators andthe stratification of the hierarchy also hold for suitablerestrictions of the operators with respect to the polynomialhierarchy if one starts with the polynomial-time computablefunctions. It follows that questions around P vs. NP andNP vs. coNP can equivalently be expressed by closureproperties of function classes under these operators. The polytime version of the first value operator can be used toestablish hierarchies between certain consecutive levels withinthe polynomial hierarchy of functions, which are related togeneralizations of the Boolean hierarchies over the classes $\mbox{$\Sigma^p_{k}$}$
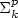 .
.
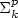
New Graph Polynomials from the Bethe Approximation of the Ising Partition Function
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 2 / March 2011
- Published online by Cambridge University Press:
- 30 June 2010, pp. 299-320
-
- Article
- Export citation
Part III - Learning Theory and Cryptography
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 195-196
-
- Chapter
- Export citation
13 - Neural Networks and Boolean Functions
- from Part IV - Graph Representations and Efficient Computation Models
-
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 554-576
-
- Chapter
- Export citation
4 - Probabilistic Analysis of Satisfiability Algorithms
- from Part II - Logic
-
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 99-159
-
- Chapter
- Export citation
Contents
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp v-vi
-
- Chapter
- Export citation
Part IV - Graph Representations and Efficient Computation Models
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 471-472
-
- Chapter
- Export citation
8 - Boolean Functions for Cryptography and Error-Correcting Codes
- from Part III - Learning Theory and Cryptography
-
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 257-397
-
- Chapter
- Export citation
Part IV - Applications in Engineering
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 597-598
-
- Chapter
- Export citation
Introduction
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp ix-xii
-
- Chapter
- Export citation
6 - Probabilistic Learning and Boolean Functions
- from Part III - Learning Theory and Cryptography
-
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 197-220
-
- Chapter
- Export citation
Part I - Algebraic Structures
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 1-2
-
- Chapter
- Export citation
5 - Optimization Methods in Logic
- from Part II - Logic
-
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 160-194
-
- Chapter
- Export citation
14 - Decision Lists and Related Classes of Boolean Functions
- from Part IV - Graph Representations and Efficient Computation Models
-
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 577-596
-
- Chapter
- Export citation
10 - Binary Decision Diagrams
- from Part IV - Graph Representations and Efficient Computation Models
-
-
- Book:
- Boolean Models and Methods in Mathematics, Computer Science, and Engineering
- Published online:
- 05 June 2013
- Print publication:
- 28 June 2010, pp 473-505
-
- Chapter
- Export citation
