Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
On the Number of Perfect Matchings in Random Lifts
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 09 June 2010, pp. 791-817
-
- Article
- Export citation
Decompositions into Subgraphs of Small Diameter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 09 June 2010, pp. 753-774
-
- Article
- Export citation
Testing Expansion in Bounded-Degree Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 5-6 / November 2010
- Published online by Cambridge University Press:
- 09 June 2010, pp. 693-709
-
- Article
- Export citation
-
We consider the problem of testing expansion in bounded-degree graphs. We focus on the notion of vertex expansion: an α-expander is a graph G = (V, E) in which every subset U ⊆ V of at most |V|/2 vertices has a neighbourhood of size at least α ⋅ |U|. Our main result is that one can distinguish good expanders from graphs that are far from being weak expanders in time
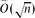 . We prove that the property-testing algorithm proposed by Goldreich and Ron with appropriately set parameters accepts every α-expander with probability at least
. We prove that the property-testing algorithm proposed by Goldreich and Ron with appropriately set parameters accepts every α-expander with probability at least  and rejects every graph that is ϵ-far from any α*-expander with probability at least , where
and rejects every graph that is ϵ-far from any α*-expander with probability at least , where 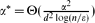 and d is the maximum degree of the graphs. The algorithm assumes the bounded-degree graphs model with adjacency list graph representation and its running time is
and d is the maximum degree of the graphs. The algorithm assumes the bounded-degree graphs model with adjacency list graph representation and its running time is 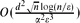 .
.
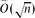 . We prove that the property-testing algorithm proposed by Goldreich and Ron with appropriately set parameters accepts every α-expander with probability at least
. We prove that the property-testing algorithm proposed by Goldreich and Ron with appropriately set parameters accepts every α-expander with probability at least  and rejects every graph that is ϵ-far from any α*-expander with probability at least
and rejects every graph that is ϵ-far from any α*-expander with probability at least 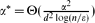 and
and 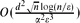 .
.The Largest Component in Subcritical Inhomogeneous Random Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 09 June 2010, pp. 131-154
-
- Article
- Export citation
Permuting machines and permutation patterns
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 67-88
-
- Chapter
- Export citation
A survey on partially ordered patterns
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 115-136
-
- Chapter
- Export citation
An introduction to structural methods in permutation patterns
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 153-170
-
- Chapter
- Export citation
Enumeration of partitions by rises, levels and descents
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 221-232
-
- Chapter
- Export citation
Generalized permutation patterns – a short survey
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 137-152
-
- Chapter
- Export citation
Some general results in combinatorial enumeration
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 3-40
-
- Chapter
- Export citation
Packing rates of measures and a conjecture for the packing density of 2413
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 287-316
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp i-iv
-
- Chapter
- Export citation
Problems and conjectures
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 339-345
-
- Chapter
- Export citation
A survey of simple permutations
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 41-66
-
- Chapter
- Export citation
The lexicographic first occurrence of a I-II-III-pattern
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 213-220
-
- Chapter
- Export citation
Contents
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp v-vi
-
- Chapter
- Export citation
Combinatorial properties of permutation tableaux
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 171-192
-
- Chapter
- Export citation
Preface
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp vii-viii
-
- Chapter
- Export citation
On the permutational power of token passing networks
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 317-338
-
- Chapter
- Export citation
On three different notions of monotone subsequences
-
-
- Book:
- Permutation Patterns
- Published online:
- 05 October 2010
- Print publication:
- 03 June 2010, pp 89-114
-
- Chapter
- Export citation
