Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
CPC volume 19 issue 3 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 3 / May 2010
- Published online by Cambridge University Press:
- 25 March 2010, pp. f1-f2
-
- Article
-
- You have access
- Export citation

Updating Logical Databases
-
- Published online:
- 22 March 2010
- Print publication:
- 26 October 1990

Hybrid Graph Theory and Network Analysis
-
- Published online:
- 20 March 2010
- Print publication:
- 02 September 1999

Paradigms for Fast Parallel Approximability
-
- Published online:
- 19 March 2010
- Print publication:
- 10 July 1997
First-Passage Percolation with Exponential Times on a Ladder
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 4 / July 2010
- Published online by Cambridge University Press:
- 19 March 2010, pp. 593-601
-
- Article
- Export citation
Playing to Retain the Advantage
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 4 / July 2010
- Published online by Cambridge University Press:
- 19 March 2010, pp. 481-491
-
- Article
- Export citation

Programs, Recursion and Unbounded Choice
-
- Published online:
- 11 March 2010
- Print publication:
- 21 May 1992
Random Records and Cuttings in Binary Search Trees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 3 / May 2010
- Published online by Cambridge University Press:
- 05 March 2010, pp. 391-424
-
- Article
- Export citation
On Percolation and the Bunkbed Conjecture
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 17 February 2010, pp. 103-117
-
- Article
- Export citation
What Does a Random Contingency Table Look Like?
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 4 / July 2010
- Published online by Cambridge University Press:
- 12 February 2010, pp. 517-539
-
- Article
- Export citation

Design Theory and Computer Science
-
- Published online:
- 10 February 2010
- Print publication:
- 16 May 1991
Counting Matchings and Tree-Like Walks in Regular Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 3 / May 2010
- Published online by Cambridge University Press:
- 10 February 2010, pp. 463-480
-
- Article
- Export citation

Mathematical Explorations with MATLAB
-
- Published online:
- 08 February 2010
- Print publication:
- 15 April 1999
CPC volume 19 issue 2 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 2 / March 2010
- Published online by Cambridge University Press:
- 05 February 2010, pp. b1-b2
-
- Article
-
- You have access
- Export citation
WDM and Directed Star Arboricity
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 2 / March 2010
- Published online by Cambridge University Press:
- 05 February 2010, pp. 161-182
-
- Article
- Export citation
-
A digraph is m-labelled if every arc is labelled by an integer in {1, . . ., m}. Motivated by wavelength assignment for multicasts in optical networks, we introduce and study n-fibre colourings of labelled digraphs. These are colourings of the arcs of D such that at each vertex v, and for each colour α, in(v, α) + out(v, α) ≤ n with in(v, α) the number of arcs coloured α entering v and out(v, α) the number of labels l such that there is at least one arc of label l leaving v and coloured with α. The problem is to find the minimum number of colours λn(D) such that the m-labelled digraph D has an n-fibre colouring. In the particular case when D is 1-labelled, λ1(D) is called the directed star arboricity of D, and is denoted by dst(D). We first show that dst(D) ≤ 2Δ−(D)+1, and conjecture that if Δ−(D) ≥ 2, then dst(D) ≤ 2Δ−(D). We also prove that for a subcubic digraph D, then dst(D) ≤ 3, and that if Δ+(D), Δ−(D) ≤ 2, then dst(D) ≤ 4. Finally, we study λn(m, k) = max{λn(D) | D is m-labelled and Δ−(D) ≤ k}. We show that if m ≥ n, then
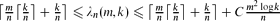 for some constant C. We conjecture that the lower bound should be the correct value of λn(m, k).
for some constant C. We conjecture that the lower bound should be the correct value of λn(m, k).
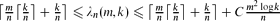 for some constant
for some constant CPC volume 19 issue 2 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 2 / March 2010
- Published online by Cambridge University Press:
- 05 February 2010, pp. f1-f2
-
- Article
-
- You have access
- Export citation

A First Course in Combinatorial Optimization
-
- Published online:
- 28 January 2010
- Print publication:
- 09 February 2004

A Unifying Framework for Structured Analysis and Design Models
- An Approach Using Initial Algebra Semantics and Category Theory
-
- Published online:
- 28 January 2010
- Print publication:
- 09 May 1991

Theories of Programming Languages
-
- Published online:
- 28 January 2010
- Print publication:
- 13 October 1998
Area Limit Laws for Symmetry Classes of Staircase Polygons
-
- Journal:
- Combinatorics, Probability and Computing / Volume 19 / Issue 3 / May 2010
- Published online by Cambridge University Press:
- 27 January 2010, pp. 441-461
-
- Article
- Export citation
