Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
PHILIPPE FLAJOLET 1 December 1948 – 22 March 2011
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 5 / September 2011
- Published online by Cambridge University Press:
- 18 August 2011, pp. 647-649
-
- Article
-
- You have access
- Export citation
On r-Cross Intersecting Families of Sets
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 5 / September 2011
- Published online by Cambridge University Press:
- 18 August 2011, pp. 749-752
-
- Article
- Export citation
-
Let (r−1)n ≥ rk and let
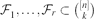 . Suppose that F1 ∩ ⋅⋅⋅ ∩ Fr ≠ ∅ holds for all Fi ∈
. Suppose that F1 ∩ ⋅⋅⋅ ∩ Fr ≠ ∅ holds for all Fi ∈ 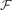
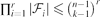 .
.
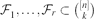 . Suppose that
. Suppose that 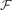
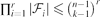 .
.On Sumsets of Convex Sets
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 5 / September 2011
- Published online by Cambridge University Press:
- 07 July 2011, pp. 793-798
-
- Article
- Export citation
A note on maximum independent sets and minimum clique partitions in unit disk graphs and penny graphs: complexity and approximation
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 3 / July 2011
- Published online by Cambridge University Press:
- 05 September 2011, pp. 331-346
- Print publication:
- July 2011
-
- Article
- Export citation
The Fibonacci automorphismof free Burnside groups
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 3 / July 2011
- Published online by Cambridge University Press:
- 26 August 2011, pp. 301-309
- Print publication:
- July 2011
-
- Article
- Export citation
-
We prove that the Fibonacci morphism is an automorphism of infinite order of free Burnside groups for all odd $n\geq 665$
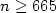 and even $n = 16k \geq 8000$
and even $n = 16k \geq 8000$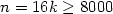 .
.
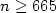
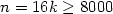
Construction of tree automata from regular expressions
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 3 / July 2011
- Published online by Cambridge University Press:
- 22 August 2011, pp. 347-370
- Print publication:
- July 2011
-
- Article
- Export citation
Locally catenative sequencesand Turtle graphics
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 3 / July 2011
- Published online by Cambridge University Press:
- 22 August 2011, pp. 311-330
- Print publication:
- July 2011
-
- Article
- Export citation
Deciding knowledge in security protocols under some e-voting theories
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 45 / Issue 3 / July 2011
- Published online by Cambridge University Press:
- 26 August 2011, pp. 269-299
- Print publication:
- July 2011
-
- Article
- Export citation
Zero Biasing and Jack Measures
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 5 / September 2011
- Published online by Cambridge University Press:
- 20 June 2011, pp. 753-762
-
- Article
- Export citation
An Improvement of the Lovász Local Lemma via Cluster Expansion
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 5 / September 2011
- Published online by Cambridge University Press:
- 20 June 2011, pp. 709-719
-
- Article
- Export citation
Karp–Sipser on Random Graphs with a Fixed Degree Sequence
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 5 / September 2011
- Published online by Cambridge University Press:
- 20 June 2011, pp. 721-741
-
- Article
- Export citation
-
Let Δ ≥ 3 be an integer. Given a fixed z ∈


First Passage Percolation on the Erdős–Rényi Random Graph
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 5 / September 2011
- Published online by Cambridge University Press:
- 20 June 2011, pp. 683-707
-
- Article
- Export citation
-
In this paper we explore first passage percolation (FPP) on the Erdős–Rényi random graph Gn(pn), where we assign independent random weights, having an exponential distribution with rate 1, to the edges. In the sparse regime, i.e., when npn → λ > 1, we find refined asymptotics both for the minimal weight of the path between uniformly chosen vertices in the giant component, as well as for the hopcount (i.e., the number of edges) on this minimal weight path. More precisely, we prove a central limit theorem for the hopcount, with asymptotic mean and variance both equal to (λ log n)/(λ − 1). Furthermore, we prove that the minimal weight centred by (log n)/(λ − 1) converges in distribution.
We also investigate the dense regime, where npn → ∞. We find that although the base graph is ultra-small (meaning that graph distances between uniformly chosen vertices are o(log n)), attaching random edge weights changes the geometry of the network completely. Indeed, the hopcount Hn satisfies the universality property that whatever the value of pn, Hn/log n → 1 in probability and, more precisely, (Hn − βn log n)/
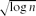
This paper continues the investigation of FPP initiated in [4] and [5]. Compared to the setting on the configuration model studied in [5], the proofs presented here are much simpler due to a direct relation between FPP on the Erdős–Rényi random graph and thinned continuous-time branching processes.
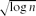
Random Graphs with Few Disjoint Cycles
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 5 / September 2011
- Published online by Cambridge University Press:
- 09 June 2011, pp. 763-775
-
- Article
- Export citation

Lectures in Game Theory for Computer Scientists
-
- Published online:
- 01 June 2011
- Print publication:
- 06 January 2011
CPC volume 20 issue 4 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 31 May 2011, pp. f1-f2
-
- Article
-
- You have access
- Export citation
CPC volume 20 issue 4 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 31 May 2011, pp. b1-b2
-
- Article
-
- You have access
- Export citation
The Maximum Degree of Series-Parallel Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 31 May 2011, pp. 529-570
-
- Article
- Export citation
-
We prove that the maximum degree Δn of a random series-parallel graph with n vertices satisfies Δn/logn → c in probability, and


Better Bounds for k-Partitions of Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 20 / Issue 4 / July 2011
- Published online by Cambridge University Press:
- 31 May 2011, pp. 631-640
-
- Article
- Export citation
-
Let G be a graph with m edges, and let k be a positive integer. We show that V(G) admits a k-partition V1, . . . Vk such that
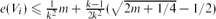 for i ∈ {1, 2, . . . k}, and
for i ∈ {1, 2, . . . k}, and 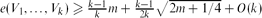 , where e(Vi) denotes the number of edges with both ends in Vi and
, where e(Vi) denotes the number of edges with both ends in Vi and 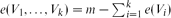 . This answers a problem of Bollobás and Scott [2] in the affirmative. Moreover,
. This answers a problem of Bollobás and Scott [2] in the affirmative. Moreover, 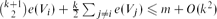 for i ∈ {1, 2, . . ., k}, which is close to being best possible and settles another problem of Bollobás and Scott [2].
for i ∈ {1, 2, . . ., k}, which is close to being best possible and settles another problem of Bollobás and Scott [2].
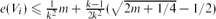 for
for 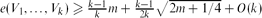 , where
, where 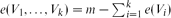 . This answers a problem of Bollobás and Scott [2] in the affirmative. Moreover,
. This answers a problem of Bollobás and Scott [2] in the affirmative. Moreover, 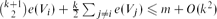 for
for 3 - Rounding Data and Dynamic Programming
- from I - An Introduction to the Techniques
-
- Book:
- The Design of Approximation Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 26 April 2011, pp 57-72
-
- Chapter
- Export citation
I - An Introduction to the Techniques
-
- Book:
- The Design of Approximation Algorithms
- Published online:
- 05 June 2012
- Print publication:
- 26 April 2011, pp 1-2
-
- Chapter
- Export citation
