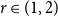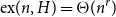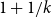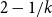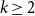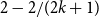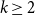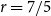Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
3 - Games in Strategic Form
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 53-76
-
- Chapter
- Export citation
12 - Correlated Equilibrium
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 333-350
-
- Chapter
- Export citation
References
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 351-357
-
- Chapter
- Export citation
Index
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 358-362
-
- Chapter
- Export citation
8 - Zero-Sum Games
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 205-222
-
- Chapter
- Export citation
5 - Expected Utility
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 103-134
-
- Chapter
- Export citation
7 - Brouwer’s Fixed-Point Theorem
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 169-204
-
- Chapter
- Export citation
Preface
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp ix-xii
-
- Chapter
- Export citation
9 - Geometry of Equilibria in Bimatrix Games
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 223-262
-
- Chapter
- Export citation
4 - Game Trees with Perfect Information
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 77-102
-
- Chapter
- Export citation
Copyright page
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp iv-iv
-
- Chapter
- Export citation
Reviews
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp ii-ii
-
- Chapter
- Export citation
1 - Nim and Combinatorial Games
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 1-38
-
- Chapter
- Export citation
Contents
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp v-viii
-
- Chapter
- Export citation
11 - Bargaining
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 299-332
-
- Chapter
- Export citation
6 - Mixed Equilibrium
-
- Book:
- Game Theory Basics
- Published online:
- 22 October 2021
- Print publication:
- 19 August 2021, pp 135-168
-
- Chapter
- Export citation
The distance profile of rooted and unrooted simply generated trees
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 3 / May 2022
- Published online by Cambridge University Press:
- 18 August 2021, pp. 368-410
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
It is well known that the height profile of a critical conditioned Galton–Watson tree with finite offspring variance converges, after a suitable normalisation, to the local time of a standard Brownian excursion. In this work, we study the distance profile, defined as the profile of all distances between pairs of vertices. We show that after a proper rescaling the distance profile converges to a continuous random function that can be described as the density of distances between random points in the Brownian continuum random tree. We show that this limiting function a.s. is Hölder continuous of any order
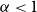 $\alpha<1$, and that it is a.e. differentiable. We note that it cannot be differentiable at 0, but leave as open questions whether it is Lipschitz, and whether it is continuously differentiable on the half-line
$\alpha<1$, and that it is a.e. differentiable. We note that it cannot be differentiable at 0, but leave as open questions whether it is Lipschitz, and whether it is continuously differentiable on the half-line 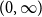 $(0,\infty)$. The distance profile is naturally defined also for unrooted trees contrary to the height profile that is designed for rooted trees. This is used in our proof, and we prove the corresponding convergence result for the distance profile of random unrooted simply generated trees. As a minor purpose of the present work, we also formalize the notion of unrooted simply generated trees and include some simple results relating them to rooted simply generated trees, which might be of independent interest.
$(0,\infty)$. The distance profile is naturally defined also for unrooted trees contrary to the height profile that is designed for rooted trees. This is used in our proof, and we prove the corresponding convergence result for the distance profile of random unrooted simply generated trees. As a minor purpose of the present work, we also formalize the notion of unrooted simply generated trees and include some simple results relating them to rooted simply generated trees, which might be of independent interest.
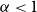
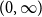

Reconstructing Networks
-
- Published online:
- 10 August 2021
- Print publication:
- 09 September 2021
-
- Element
- Export citation

The Discrete Mathematical Charms of Paul Erdos
- A Simple Introduction
-
- Published online:
- 05 August 2021
- Print publication:
- 26 August 2021
On Turán exponents of bipartite graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 04 August 2021, pp. 333-344
-
- Article
- Export citation
-
A long-standing conjecture of Erdős and Simonovits asserts that for every rational number
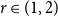 $r\in (1,2)$ there exists a bipartite graph H such that
$r\in (1,2)$ there exists a bipartite graph H such that 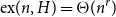 $\mathrm{ex}(n,H)=\Theta(n^r)$. So far this conjecture is known to be true only for rationals of form
$\mathrm{ex}(n,H)=\Theta(n^r)$. So far this conjecture is known to be true only for rationals of form 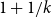 $1+1/k$ and
$1+1/k$ and 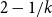 $2-1/k$, for integers
$2-1/k$, for integers 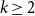 $k\geq 2$. In this paper, we add a new form of rationals for which the conjecture is true:
$k\geq 2$. In this paper, we add a new form of rationals for which the conjecture is true: 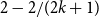 $2-2/(2k+1)$, for
$2-2/(2k+1)$, for 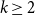 $k\geq 2$. This in turn also gives an affirmative answer to a question of Pinchasi and Sharir on cube-like graphs. Recently, a version of Erdős and Simonovits
$k\geq 2$. This in turn also gives an affirmative answer to a question of Pinchasi and Sharir on cube-like graphs. Recently, a version of Erdős and Simonovits $^{\prime}$s conjecture, where one replaces a single graph by a finite family, was confirmed by Bukh and Conlon. They proposed a construction of bipartite graphs which should satisfy Erdős and Simonovits
$^{\prime}$s conjecture, where one replaces a single graph by a finite family, was confirmed by Bukh and Conlon. They proposed a construction of bipartite graphs which should satisfy Erdős and Simonovits $^{\prime}$s conjecture. Our result can also be viewed as a first step towards verifying Bukh and Conlon
$^{\prime}$s conjecture. Our result can also be viewed as a first step towards verifying Bukh and Conlon $^{\prime}$s conjecture. We also prove an upper bound on the Turán number of theta graphs in an asymmetric setting and employ this result to obtain another new rational exponent for Turán exponents:
$^{\prime}$s conjecture. We also prove an upper bound on the Turán number of theta graphs in an asymmetric setting and employ this result to obtain another new rational exponent for Turán exponents: 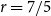 $r=7/5$.
$r=7/5$.