Refine search
Actions for selected content:
7008 results in Algorithmics, Complexity, Computer Algebra, Computational Geometry
Lower bound on the size of a quasirandom forcing set of permutations
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 27 July 2021, pp. 304-319
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A set S of permutations is forcing if for any sequence
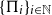 $\{\Pi_i\}_{i \in \mathbb{N}}$ of permutations where the density
$\{\Pi_i\}_{i \in \mathbb{N}}$ of permutations where the density 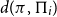 $d(\pi,\Pi_i)$ converges to
$d(\pi,\Pi_i)$ converges to 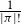 $\frac{1}{|\pi|!}$ for every permutation
$\frac{1}{|\pi|!}$ for every permutation  $\pi \in S$, it holds that
$\pi \in S$, it holds that 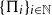 $\{\Pi_i\}_{i \in \mathbb{N}}$ is quasirandom. Graham asked whether there exists an integer k such that the set of all permutations of order k is forcing; this has been shown to be true for any
$\{\Pi_i\}_{i \in \mathbb{N}}$ is quasirandom. Graham asked whether there exists an integer k such that the set of all permutations of order k is forcing; this has been shown to be true for any 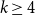 $k\ge 4$. In particular, the set of all 24 permutations of order 4 is forcing. We provide the first non-trivial lower bound on the size of a forcing set of permutations: every forcing set of permutations (with arbitrary orders) contains at least four permutations.
$k\ge 4$. In particular, the set of all 24 permutations of order 4 is forcing. We provide the first non-trivial lower bound on the size of a forcing set of permutations: every forcing set of permutations (with arbitrary orders) contains at least four permutations.
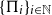
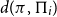

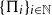
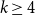
Spectral gap in random bipartite biregular graphs and applications
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 23 July 2021, pp. 229-267
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Introduction
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 1-5
-
- Chapter
- Export citation
2 - The Pigeonhole Principle and Ramsey Theory
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 42-82
-
- Chapter
- Export citation
4 - Permutations and Combinations
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 115-146
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp i-iv
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp xv-xvi
-
- Chapter
- Export citation
Hints for Selected Problems
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 524-530
-
- Chapter
- Export citation
Complete Solutions for Selected Problems
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 533-601
-
- Chapter
- Export citation
6 - Stirling Numbers
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 193-229
-
- Chapter
- Export citation
Index
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 609-614
-
- Chapter
- Export citation
Plate Section
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 615-618
-
- Chapter
- Export citation
Preface
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp xi-xiv
-
- Chapter
- Export citation
3 - Counting, Probability, Balls and Boxes
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 83-114
-
- Chapter
- Export citation
Dedication
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp v-vi
-
- Chapter
- Export citation
Bibliography
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 602-608
-
- Chapter
- Export citation
Short Answers for Selected Problems
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 531-532
-
- Chapter
- Export citation
10 - Graph Theory
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 361-452
-
- Chapter
- Export citation
Short Answers for Warm-Up Problems
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp 522-523
-
- Chapter
- Export citation
Contents
-
- Book:
- An Invitation to Combinatorics
- Published online:
- 16 September 2021
- Print publication:
- 22 July 2021, pp vii-x
-
- Chapter
- Export citation
