Refine search
Actions for selected content:
48274 results in Computer Science
Dedication
-
- Book:
- Random Wireless Networks
- Published online:
- 05 May 2015
- Print publication:
- 13 April 2015, pp iii-iv
-
- Chapter
- Export citation
REC volume 27 issue 2 Cover and Back matter
-
- Article
-
- You have access
- Export citation
9 - Throughput Capacity
-
- Book:
- Random Wireless Networks
- Published online:
- 05 May 2015
- Print publication:
- 13 April 2015, pp 202-228
-
- Chapter
- Export citation
NWS volume 3 issue 1 Cover and Front matter
-
- Journal:
- Network Science / Volume 3 / Issue 1 / March 2015
- Published online by Cambridge University Press:
- 09 April 2015, pp. f1-f3
-
- Article
-
- You have access
- Export citation
NWS volume 3 issue 1 Cover and Back matter
-
- Journal:
- Network Science / Volume 3 / Issue 1 / March 2015
- Published online by Cambridge University Press:
- 09 April 2015, pp. b1-b3
-
- Article
-
- You have access
- Export citation
Examining the literature on “Networks in Space and in Time.” An introduction
-
- Journal:
- Network Science / Volume 3 / Issue 1 / March 2015
- Published online by Cambridge University Press:
- 09 April 2015, pp. 1-17
-
- Article
- Export citation
Equational axioms associated with finite automata for fixed point operations in cartesian categories
-
- Journal:
- Mathematical Structures in Computer Science / Volume 27 / Issue 1 / January 2017
- Published online by Cambridge University Press:
- 08 April 2015, pp. 54-69
-
- Article
- Export citation
-
The axioms of iteration theories, or iteration categories, capture the equational properties of fixed point operations in several computationally significant categories. Iteration categories may be axiomatized by the Conway identities and identities associated with finite automata. We show that the Conway identities and the identities associated with the members of a subclass
 $\mathcal{Q}$ of finite automata is complete for iteration categories iff for every finite simple group G there is an automaton Q ∈ $\mathcal{Q}$ such that G is a quotient of a group in the monoid M(Q) of the automaton Q. We also prove a stronger result that concerns identities associated with finite automata with a distinguished initial state.
$\mathcal{Q}$ of finite automata is complete for iteration categories iff for every finite simple group G there is an automaton Q ∈ $\mathcal{Q}$ such that G is a quotient of a group in the monoid M(Q) of the automaton Q. We also prove a stronger result that concerns identities associated with finite automata with a distinguished initial state.

INFINITARY TABLEAU FOR SEMANTIC TRUTH
-
- Journal:
- The Review of Symbolic Logic / Volume 8 / Issue 2 / June 2015
- Published online by Cambridge University Press:
- 08 April 2015, pp. 207-235
- Print publication:
- June 2015
-
- Article
- Export citation
-
We provide infinitary proof theories for three common semantic theories of truth: strong Kleene, van Fraassen supervaluation and Cantini supervaluation. The value of these systems is that they provide an easy method of proving simple facts about semantic theories. Moreover we shall show that they also give us a simpler understanding of the computational complexity of these definitions and provide a direct proof that the closure ordinal for Kripke’s definition is
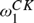 $\omega _1^{CK}$. This work can be understood as an effort to provide a proof-theoretic counterpart to Welch’s game-theoretic (Welch, 2009).
$\omega _1^{CK}$. This work can be understood as an effort to provide a proof-theoretic counterpart to Welch’s game-theoretic (Welch, 2009).

Large Sample Covariance Matrices and High-Dimensional Data Analysis
-
- Published online:
- 05 April 2015
- Print publication:
- 26 March 2015
-
- Book
- Export citation
BIBLIOGRAPHY
-
- Book:
- Pure Inductive Logic
- Published online:
- 05 May 2015
- Print publication:
- 02 April 2015, pp 327-336
-
- Chapter
- Export citation
Chapter 22 - Principles of Analogy
- from Part 2 - Unary Pure Inductive Logic
-
- Book:
- Pure Inductive Logic
- Published online:
- 05 May 2015
- Print publication:
- 02 April 2015, pp 165-170
-
- Chapter
- Export citation
Chapter 43 - Less Well Travelled Roads
- from Part 3 - Polyadic Pure Inductive Logic
-
- Book:
- Pure Inductive Logic
- Published online:
- 05 May 2015
- Print publication:
- 02 April 2015, pp 323-326
-
- Chapter
- Export citation
Chapter 24 - Introduction to Polyadic Pure Inductive Logic
- from Part 3 - Polyadic Pure Inductive Logic
-
- Book:
- Pure Inductive Logic
- Published online:
- 05 May 2015
- Print publication:
- 02 April 2015, pp 181-182
-
- Chapter
- Export citation
Chapter 40 - Similarity
- from Part 3 - Polyadic Pure Inductive Logic
-
- Book:
- Pure Inductive Logic
- Published online:
- 05 May 2015
- Print publication:
- 02 April 2015, pp 303-310
-
- Chapter
- Export citation
Chapter 19 - The NP-Continuum
- from Part 2 - Unary Pure Inductive Logic
-
- Book:
- Pure Inductive Logic
- Published online:
- 05 May 2015
- Print publication:
- 02 April 2015, pp 135-142
-
- Chapter
- Export citation
Chapter 5 - The Dutch Book Argument
- from Part 1 - The Basics
-
- Book:
- Pure Inductive Logic
- Published online:
- 05 May 2015
- Print publication:
- 02 April 2015, pp 25-32
-
- Chapter
- Export citation
Chapter 10 - Regularity and Universal Certainty
- from Part 2 - Unary Pure Inductive Logic
-
- Book:
- Pure Inductive Logic
- Published online:
- 05 May 2015
- Print publication:
- 02 April 2015, pp 61-68
-
- Chapter
- Export citation
Chapter 11 - Relevance
- from Part 2 - Unary Pure Inductive Logic
-
- Book:
- Pure Inductive Logic
- Published online:
- 05 May 2015
- Print publication:
- 02 April 2015, pp 69-72
-
- Chapter
- Export citation
