Refine search
Actions for selected content:
48284 results in Computer Science
1 - The Beginnings of Social Media Intelligence
- from Part I - Foundations
-
- Book:
- Social Media Intelligence
- Published online:
- 05 February 2014
- Print publication:
- 24 February 2014, pp 3-17
-
- Chapter
- Export citation
3 - Why Do We Share Our Opinions?
- from Part II - Online Opinion or Online Noise
-
- Book:
- Social Media Intelligence
- Published online:
- 05 February 2014
- Print publication:
- 24 February 2014, pp 37-52
-
- Chapter
- Export citation
Selection of correction candidates for the normalization of Spanish user-generated content
-
- Journal:
- Natural Language Engineering / Volume 22 / Issue 1 / January 2016
- Published online by Cambridge University Press:
- 24 February 2014, pp. 135-161
-
- Article
- Export citation
Contents
-
- Book:
- Social Media Intelligence
- Published online:
- 05 February 2014
- Print publication:
- 24 February 2014, pp v-viii
-
- Chapter
- Export citation
2 - Fundamentals of Opinion Formation
- from Part I - Foundations
-
- Book:
- Social Media Intelligence
- Published online:
- 05 February 2014
- Print publication:
- 24 February 2014, pp 18-34
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Social Media Intelligence
- Published online:
- 05 February 2014
- Print publication:
- 24 February 2014, pp i-iv
-
- Chapter
- Export citation
Robust Analysis of Preferential Attachment Models with Fitness
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 24 February 2014, pp. 386-411
-
- Article
- Export citation
EXPRESSIVE LIMITATIONS OF NAÏVE SET THEORY IN LP AND MINIMALLY INCONSISTENT LP.
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 2 / June 2014
- Published online by Cambridge University Press:
- 21 February 2014, pp. 341-350
- Print publication:
- June 2014
-
- Article
- Export citation
-
We give some negative results on the expressiveness of naïve set theory (NS) in LP and in the four variants of minimally inconsistent LP defined in Crabbé (2011):
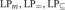 ${\rm{L}}{{\rm{P}}_m},{\rm{L}}{{\rm{P}}_ = },{\rm{L}}{{\rm{P}}_ \subseteq }$, and
${\rm{L}}{{\rm{P}}_m},{\rm{L}}{{\rm{P}}_ = },{\rm{L}}{{\rm{P}}_ \subseteq }$, and 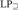 ${\rm{L}}{{\rm{P}}_ \supseteq }$. We show that NS in LP cannot prove the existence of sets that behave like singleton sets, Cartesian pairs, or infinitely ascending linear orders. We show that NS is close to trivial in
${\rm{L}}{{\rm{P}}_ \supseteq }$. We show that NS in LP cannot prove the existence of sets that behave like singleton sets, Cartesian pairs, or infinitely ascending linear orders. We show that NS is close to trivial in 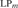 ${\rm{L}}{{\rm{P}}_m}$ and
${\rm{L}}{{\rm{P}}_m}$ and 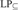 ${\rm{L}}{{\rm{P}}_ \subseteq }$, in the sense that its only minimally inconsistent model is a one-element model. We show that NS in
${\rm{L}}{{\rm{P}}_ \subseteq }$, in the sense that its only minimally inconsistent model is a one-element model. We show that NS in 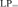 ${\rm{L}}{{\rm{P}}_ = }$ and
${\rm{L}}{{\rm{P}}_ = }$ and 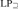 ${\rm{L}}{{\rm{P}}_ \supseteq }$ has the same limitations we give for NS in LP.
${\rm{L}}{{\rm{P}}_ \supseteq }$ has the same limitations we give for NS in LP.
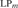
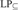
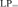
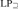
CPC volume 23 issue 2 Cover and Back matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 2 / March 2014
- Published online by Cambridge University Press:
- 19 February 2014, pp. b1-b7
-
- Article
-
- You have access
- Export citation
CPC volume 23 issue 2 Cover and Front matter
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 2 / March 2014
- Published online by Cambridge University Press:
- 19 February 2014, pp. f1-f2
-
- Article
-
- You have access
- Export citation
aspeed: Solver scheduling via answer set programming1
-
- Journal:
- Theory and Practice of Logic Programming / Volume 15 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 17 February 2014, pp. 117-142
-
- Article
- Export citation
LOGICISM, INTERPRETABILITY, AND KNOWLEDGE OF ARITHMETIC
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 1 / March 2014
- Published online by Cambridge University Press:
- 14 February 2014, pp. 84-119
- Print publication:
- March 2014
-
- Article
- Export citation
2 - Introduction to stream processing
- from Part 1 - Fundamentals
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 33-74
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp i-iv
-
- Chapter
- Export citation
