Refine search
Actions for selected content:
48274 results in Computer Science
11 - Stream analytics: modeling and evaluation
- from Part IV - Application design and analytics
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 388-438
-
- Chapter
- Export citation
4 - Application development – data flow programming
- from Part II - Application development
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 106-147
-
- Chapter
- Export citation
7 - Architecture of a stream processing system
- from Part III - System architecture
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 203-217
-
- Chapter
- Export citation
10 - Stream analytics: data pre-processing and transformation
- from Part IV - Application design and analytics
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 342-387
-
- Chapter
- Export citation
Part V - Case studies
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 439-440
-
- Chapter
- Export citation
Part VI - Closing notes
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 485-486
-
- Chapter
- Export citation
Dedication
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp v-vi
-
- Chapter
- Export citation
Index
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 504-529
-
- Chapter
- Export citation
6 - Visualization and debugging
- from Part II - Application development
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 178-200
-
- Chapter
- Export citation
Part IV - Application design and analytics
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 273-274
-
- Chapter
- Export citation
Local Limit Theorems for the Giant Component of Random Hypergraphs†
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 13 February 2014, pp. 331-366
-
- Article
- Export citation
-
Let Hd(n,p) signify a random d-uniform hypergraph with n vertices in which each of the
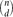 $\binom{n}{d}$ possible edges is present with probability p=p(n) independently, and let Hd(n,m) denote a uniformly distributed d-uniform hypergraph with n vertices and m edges. We derive local limit theorems for the joint distribution of the number of vertices and the number of edges in the largest component of Hd(n,p) and Hd(n,m) in the regime
$\binom{n}{d}$ possible edges is present with probability p=p(n) independently, and let Hd(n,m) denote a uniformly distributed d-uniform hypergraph with n vertices and m edges. We derive local limit theorems for the joint distribution of the number of vertices and the number of edges in the largest component of Hd(n,p) and Hd(n,m) in the regime 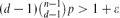 $(d-1)\binom{n-1}{d-1}p>1+\varepsilon$, resp. d(d−1)m/n>1+ϵ, where ϵ>0 is arbitrarily small but fixed as n → ∞. The proofs are based on a purely probabilistic approach.
$(d-1)\binom{n-1}{d-1}p>1+\varepsilon$, resp. d(d−1)m/n>1+ϵ, where ϵ>0 is arbitrarily small but fixed as n → ∞. The proofs are based on a purely probabilistic approach.
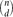
1 - What brought us here?
- from Part 1 - Fundamentals
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 3-32
-
- Chapter
- Export citation
Contents
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp vii-xii
-
- Chapter
- Export citation
Keywords and identifiers index
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 500-503
-
- Chapter
- Export citation
Part II - Application development
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 75-76
-
- Chapter
- Export citation
13 - Conclusion
- from Part VI - Closing notes
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 487-499
-
- Chapter
- Export citation
Acknowledgements
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp xxi-xxi
-
- Chapter
- Export citation
Part 1 - Fundamentals
-
- Book:
- Fundamentals of Stream Processing
- Published online:
- 05 March 2014
- Print publication:
- 13 February 2014, pp 1-2
-
- Chapter
- Export citation
