Refine search
Actions for selected content:
48274 results in Computer Science
Part 5 - Heuristics
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 329-330
-
- Chapter
- Export citation
Part 1 - Graphical Structure
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 1-2
-
- Chapter
- Export citation
Contributors
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp xi-xii
-
- Chapter
- Export citation
6 - Tree-Reweighted Message Passing
- from Part 3 - Algorithms and their Analysis
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 175-201
-
- Chapter
- Export citation
Contents
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp v-x
-
- Chapter
- Export citation
10 - Efficient Submodular Function Minimization for Computer Vision
- from Part 4 - Tractability in Some Specific Areas
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 285-303
-
- Chapter
- Export citation
Part 2 - Language Restrictions
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 69-70
-
- Chapter
- Export citation
5 - Tractable Knowledge Representation Formalisms
- from Part 2 - Language Restrictions
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 141-172
-
- Chapter
- Export citation
9 - Kernelization Methods for Fixed-Parameter Tractability
- from Part 3 - Algorithms and their Analysis
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp 260-282
-
- Chapter
- Export citation
Introduction
-
-
- Book:
- Tractability
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014, pp xiii-xxii
-
- Chapter
- Export citation

Social Media Intelligence
-
- Published online:
- 05 February 2014
- Print publication:
- 24 February 2014

SuperFractals
-
- Published online:
- 05 February 2014
- Print publication:
- 07 September 2006

Calendrical Calculations
-
- Published online:
- 05 February 2014
- Print publication:
- 10 December 2007

Tractability
- Practical Approaches to Hard Problems
-
- Published online:
- 05 February 2014
- Print publication:
- 06 February 2014
On the Diameters of Commuting Graphs Arising from Random Skew-Symmetric Matrices
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 3 / May 2014
- Published online by Cambridge University Press:
- 04 February 2014, pp. 449-459
-
- Article
- Export citation
-
We present a two-parameter family
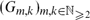 $(G_{m,k})_{m, k \in \mathbb{N}_{\geq 2}}$, of finite, non-abelian random groups and propose that, for each fixed k, as m → ∞ the commuting graph of Gm,k is almost surely connected and of diameter k. We present heuristic arguments in favour of this conjecture, following the lines of classical arguments for the Erdős–Rényi random graph. As well as being of independent interest, our groups would, if our conjecture is true, provide a large family of counterexamples to the conjecture of Iranmanesh and Jafarzadeh that the commuting graph of a finite group, if connected, must have a bounded diameter. Simulations of our model yielded explicit examples of groups whose commuting graphs have all diameters from 2 up to 10.
$(G_{m,k})_{m, k \in \mathbb{N}_{\geq 2}}$, of finite, non-abelian random groups and propose that, for each fixed k, as m → ∞ the commuting graph of Gm,k is almost surely connected and of diameter k. We present heuristic arguments in favour of this conjecture, following the lines of classical arguments for the Erdős–Rényi random graph. As well as being of independent interest, our groups would, if our conjecture is true, provide a large family of counterexamples to the conjecture of Iranmanesh and Jafarzadeh that the commuting graph of a finite group, if connected, must have a bounded diameter. Simulations of our model yielded explicit examples of groups whose commuting graphs have all diameters from 2 up to 10.
ENTROPY OF SOME MODELS OF SPARSE RANDOM GRAPHS WITH VERTEX-NAMES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 28 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 31 January 2014, pp. 145-168
-
- Article
- Export citation
