Refine search
Actions for selected content:
48285 results in Computer Science
One-class classification: taxonomy of study and review of techniques
-
- Journal:
- The Knowledge Engineering Review / Volume 29 / Issue 3 / June 2014
- Published online by Cambridge University Press:
- 24 January 2014, pp. 345-374
-
- Article
-
- You have access
- HTML
- Export citation
ON FLATTENING ELIMINATION RULES
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 1 / March 2014
- Published online by Cambridge University Press:
- 23 January 2014, pp. 60-72
- Print publication:
- March 2014
-
- Article
- Export citation
An application of answer set programming to the field of second language acquisition
-
- Journal:
- Theory and Practice of Logic Programming / Volume 15 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 22 January 2014, pp. 1-17
-
- Article
- Export citation
THE QUANTIFIED ARGUMENT CALCULUS
-
- Journal:
- The Review of Symbolic Logic / Volume 7 / Issue 1 / March 2014
- Published online by Cambridge University Press:
- 22 January 2014, pp. 120-146
- Print publication:
- March 2014
-
- Article
- Export citation
Delimited control and computational effects
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 24 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 22 January 2014, pp. 1-55
-
- Article
-
- You have access
- Export citation
One-Rule Length-Preserving Rewrite Systems and RationalTransductions
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 48 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 21 January 2014, pp. 149-171
- Print publication:
- April 2014
-
- Article
- Export citation
A CAPACITATED REPLENISHMENT-LIQUIDATION MODEL UNDER CONTRACTUAL AND SPOT MARKETS WITH STOCHASTIC DEMAND
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 28 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 21 January 2014, pp. 223-269
-
- Article
- Export citation
Incremental DFA minimisation∗
-
- Journal:
- RAIRO - Theoretical Informatics and Applications / Volume 48 / Issue 2 / April 2014
- Published online by Cambridge University Press:
- 21 January 2014, pp. 173-186
- Print publication:
- April 2014
-
- Article
- Export citation
Design problem solving with biological analogies: A verbal protocol study
-
- Article
-
- You have access
- HTML
- Export citation
Elaborating intersection and union types
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 24 / Issue 2-3 / May 2014
- Published online by Cambridge University Press:
- 20 January 2014, pp. 133-165
-
- Article
-
- You have access
- Export citation
AIE volume 28 issue 1 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Dynamic scheduling of manufacturing systems using machine learning: An updated review
-
- Article
-
- You have access
- HTML
- Export citation
AIE volume 28 issue 1 Cover and Back matter
-
- Article
-
- You have access
- Export citation
On the Importance Sampling of Self-Avoiding Walks
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 5 / September 2014
- Published online by Cambridge University Press:
- 20 January 2014, pp. 725-748
-
- Article
- Export citation
-
In a 1976 paper published in Science, Knuth presented an algorithm to sample (non-uniform) self-avoiding walks crossing a square of side k. From this sample, he constructed an estimator for the number of such walks. The quality of this estimator is directly related to the (relative) variance of a certain random variable Xk. From his experiments, Knuth suspected that this variance was extremely large (so that the estimator would not be very efficient). But how large? For the analogous Rosenbluth algorithm, which samples unconfined self-avoiding walks of length n, the variance of the corresponding estimator is believed to be exponential in n.
A few years ago, Bassetti and Diaconis showed that, for a sampler à la Knuth that generates walks crossing a k × k square and consisting of North and East steps, the relative variance is only
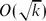 $O(\sqrt k)$. In this note we take one step further and show that, for walks consisting of North, South and East steps, the relative variance jumps to
$O(\sqrt k)$. In this note we take one step further and show that, for walks consisting of North, South and East steps, the relative variance jumps to 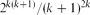 $2^{k(k+1)}/(k+1)^{2k}$. This is exponential in the average length of the walks, which is of order k2. We also obtain partial results for general self-avoiding walks crossing a square, suggesting that the relative variance could be exponential in k2 (which is again the average length of these walks).
$2^{k(k+1)}/(k+1)^{2k}$. This is exponential in the average length of the walks, which is of order k2. We also obtain partial results for general self-avoiding walks crossing a square, suggesting that the relative variance could be exponential in k2 (which is again the average length of these walks).Knuth's algorithm is a basic example of a widely used technique called sequential importance sampling. The present paper, following the paper by Bassetti and Diaconis, is one of very few examples where the variance of the estimator can be found.