Refine search
Actions for selected content:
48240 results in Computer Science
13 - Semantics for Quantified Modal Logics
-
- Book:
- Modal Logic for Philosophers
- Published online:
- 05 June 2014
- Print publication:
- 25 November 2013, pp 263-300
-
- Chapter
- Export citation
3 - Basic Concepts of Intensional Semantics
-
- Book:
- Modal Logic for Philosophers
- Published online:
- 05 June 2014
- Print publication:
- 25 November 2013, pp 57-71
-
- Chapter
- Export citation
4 - Trees for K
-
- Book:
- Modal Logic for Philosophers
- Published online:
- 05 June 2014
- Print publication:
- 25 November 2013, pp 72-92
-
- Chapter
- Export citation
18 - Descriptions
-
- Book:
- Modal Logic for Philosophers
- Published online:
- 05 June 2014
- Print publication:
- 25 November 2013, pp 383-406
-
- Chapter
- Export citation
12 - Systems for Quantified Modal Logic
-
- Book:
- Modal Logic for Philosophers
- Published online:
- 05 June 2014
- Print publication:
- 25 November 2013, pp 226-262
-
- Chapter
- Export citation
Introduction: What Is Modal Logic?
-
- Book:
- Modal Logic for Philosophers
- Published online:
- 05 June 2014
- Print publication:
- 25 November 2013, pp 1-2
-
- Chapter
- Export citation
19 - Lambda Abstraction
-
- Book:
- Modal Logic for Philosophers
- Published online:
- 05 June 2014
- Print publication:
- 25 November 2013, pp 407-429
-
- Chapter
- Export citation
RSL volume 6 issue 4 Cover and Back matter
-
- Journal:
- The Review of Symbolic Logic / Volume 6 / Issue 4 / December 2013
- Published online by Cambridge University Press:
- 22 November 2013, pp. b1-b4
- Print publication:
- December 2013
-
- Article
-
- You have access
- Export citation
RSL volume 6 issue 4 Cover and Front matter
-
- Journal:
- The Review of Symbolic Logic / Volume 6 / Issue 4 / December 2013
- Published online by Cambridge University Press:
- 22 November 2013, pp. f1-f4
- Print publication:
- December 2013
-
- Article
-
- You have access
- Export citation
Greedy Random Walk
-
- Journal:
- Combinatorics, Probability and Computing / Volume 23 / Issue 2 / March 2014
- Published online by Cambridge University Press:
- 20 November 2013, pp. 269-289
-
- Article
- Export citation
-
We study a discrete time self-interacting random process on graphs, which we call greedy random walk. The walker is located initially at some vertex. As time evolves, each vertex maintains the set of adjacent edges touching it that have not yet been crossed by the walker. At each step, the walker, being at some vertex, picks an adjacent edge among the edges that have not traversed thus far according to some (deterministic or randomized) rule. If all the adjacent edges have already been traversed, then an adjacent edge is chosen uniformly at random. After picking an edge the walker jumps along it to the neighbouring vertex. We show that the expected edge cover time of the greedy random walk is linear in the number of edges for certain natural families of graphs. Examples of such graphs include the complete graph, even degree expanders of logarithmic girth, and the hypercube graph. We also show that GRW is transient in
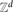 $\mathbb{Z}^d$ for all d ≥ 3.
$\mathbb{Z}^d$ for all d ≥ 3.
COMPARISONS OF SERIES AND PARALLEL SYSTEMS WITH HETEROGENEOUS COMPONENTS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 28 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 19 November 2013, pp. 39-53
-
- Article
- Export citation
PREVENTION OF CATASTROPHIC FAILURES WITH WEAK FOREWARNING SIGNALS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 28 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 19 November 2013, pp. 121-144
-
- Article
- Export citation
THE RE-OPENING OF DUBINS AND SAVAGE CASINO IN THE ERA OF DIVERSIFICATION
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 28 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 19 November 2013, pp. 55-65
-
- Article
- Export citation
PERMUTATIONAL METHODS FOR PERFORMANCE ANALYSIS OF STOCHASTIC FLOW NETWORKS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 28 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 19 November 2013, pp. 21-38
-
- Article
- Export citation
THE ISRAELI QUEUE WITH INFINITE NUMBER OF GROUPS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 28 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 19 November 2013, pp. 1-19
-
- Article
- Export citation
BUILDING RANDOM TREES FROM BLOCKS*
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 28 / Issue 1 / January 2014
- Published online by Cambridge University Press:
- 19 November 2013, pp. 67-81
-
- Article
- Export citation
