Refine search
Actions for selected content:
49487 results in Computer Science
13 - Mixed-State Entanglement
- from Part IV - Entanglement Theory
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp 538-623
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp i-iv
-
- Chapter
- Export citation
9 - Subdivisions and Triangulations
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp 258-295
-
- Chapter
- Export citation
Space-scale exploration of the poor reliability of deep learning models: the case of the remote sensing of rooftop photovoltaic systems
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 10 April 2025, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
1 - The Rise of Automated Customer Service
-
- Book:
- Automated Agencies
- Published online:
- 03 April 2025
- Print publication:
- 10 April 2025, pp 12-25
-
- Chapter
- Export citation
11 - Manipulation of Resources
- from Part III - The General Framework of Resource Theories
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp 467-504
-
- Chapter
- Export citation
5 - View from the Inside
-
- Book:
- Automated Agencies
- Published online:
- 03 April 2025
- Print publication:
- 10 April 2025, pp 95-109
-
- Chapter
- Export citation
4 - The Topological Representation Theorem
-
- Book:
- Oriented Matroids
- Published online:
- 04 June 2025
- Print publication:
- 10 April 2025, pp 103-135
-
- Chapter
- Export citation
10 - Quantification of Quantum Resources
- from Part III - The General Framework of Resource Theories
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp 426-466
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp i-iv
-
- Chapter
- Export citation
7 - Conditional Entropy
- from Part II - Tools and Methods
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp 308-351
-
- Chapter
- Export citation
Dedication
-
- Book:
- Automated Agencies
- Published online:
- 03 April 2025
- Print publication:
- 10 April 2025, pp v-vi
-
- Chapter
- Export citation
8 - The Asymptotic Regime
- from Part II - Tools and Methods
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp 352-400
-
- Chapter
- Export citation
16 - The Resource Theory of Nonuniformity
- from Part V - Additional Examples of Static Resource Theories
-
- Book:
- Quantum Resource Theories
- Published online:
- 03 May 2025
- Print publication:
- 10 April 2025, pp 736-748
-
- Chapter
- Export citation
Two-layered logics for probabilities and belief functions over Belnap–Dunn logic
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 08 April 2025, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper is an extended version of Bílková et al. ((2023b). Logic, Language, Information, and Computation. WoLLIC 2023, Lecture Notes in Computer Science, vol. 13923, Cham, Springer Nature Switzerland, 101–117.). We discuss two-layered logics formalising reasoning with probabilities and belief functions that combine the Łukasiewicz
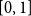 $[0,1]$-valued logic with Baaz
$[0,1]$-valued logic with Baaz 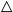 $\triangle$ operator and the Belnap–Dunn logic. We consider two probabilistic logics –
$\triangle$ operator and the Belnap–Dunn logic. We consider two probabilistic logics – 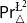 $\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}^2}_\triangle$ (introduced by Bílková et al. 2023d. Annals of Pure and Applied Logic, 103338.) and
$\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}^2}_\triangle$ (introduced by Bílková et al. 2023d. Annals of Pure and Applied Logic, 103338.) and 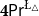 $\mathbf {4}\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}_\triangle }$ (from Bílková et al. 2023b. Logic, Language, Information, and Computation. WoLLIC 2023, Lecture Notes in Computer Science, vol. 13923, Cham, Springer Nature Switzerland, 101–117.) – that present two perspectives on the probabilities in the Belnap–Dunn logic. In
$\mathbf {4}\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}_\triangle }$ (from Bílková et al. 2023b. Logic, Language, Information, and Computation. WoLLIC 2023, Lecture Notes in Computer Science, vol. 13923, Cham, Springer Nature Switzerland, 101–117.) – that present two perspectives on the probabilities in the Belnap–Dunn logic. In 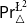 $\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}^2}_\triangle$, every event
$\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}^2}_\triangle$, every event 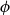 $\phi$ has independent positive and negative measures that denote the likelihoods of
$\phi$ has independent positive and negative measures that denote the likelihoods of 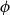 $\phi$ and
$\phi$ and 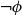 $\neg \phi$, respectively. In
$\neg \phi$, respectively. In 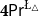 $\mathbf {4}\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}_\triangle }$, the measures of the events are treated as partitions of the sample into four exhaustive and mutually exclusive parts corresponding to pure belief, pure disbelief, conflict and uncertainty of an agent in
$\mathbf {4}\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}_\triangle }$, the measures of the events are treated as partitions of the sample into four exhaustive and mutually exclusive parts corresponding to pure belief, pure disbelief, conflict and uncertainty of an agent in 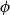 $\phi$. In addition to that, we discuss two logics for the paraconsistent reasoning with belief and plausibility functions from Bílková et al. ((2023d). Annals of Pure and Applied Logic, 103338.) –
$\phi$. In addition to that, we discuss two logics for the paraconsistent reasoning with belief and plausibility functions from Bílková et al. ((2023d). Annals of Pure and Applied Logic, 103338.) – 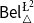 $\mathsf {Bel}^{{\mathsf {\unicode {x0141}}}^2}_\triangle$ and
$\mathsf {Bel}^{{\mathsf {\unicode {x0141}}}^2}_\triangle$ and 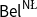 $\mathsf {Bel}^{\mathsf {N}{\mathsf {\unicode {x0141}}}}$. Both these logics equip events with two measures (positive and negative) with their main difference being that in
$\mathsf {Bel}^{\mathsf {N}{\mathsf {\unicode {x0141}}}}$. Both these logics equip events with two measures (positive and negative) with their main difference being that in 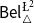 $\mathsf {Bel}^{{\mathsf {\unicode {x0141}}}^2}_\triangle$, the negative measure of
$\mathsf {Bel}^{{\mathsf {\unicode {x0141}}}^2}_\triangle$, the negative measure of 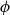 $\phi$ is defined as the belief in
$\phi$ is defined as the belief in 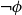 $\neg \phi$ while in
$\neg \phi$ while in 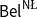 $\mathsf {Bel}^{\mathsf {N}{\mathsf {\unicode {x0141}}}}$, it is treated independently as the plausibility of
$\mathsf {Bel}^{\mathsf {N}{\mathsf {\unicode {x0141}}}}$, it is treated independently as the plausibility of 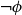 $\neg \phi$. We provide a sound and complete Hilbert-style axiomatisation of
$\neg \phi$. We provide a sound and complete Hilbert-style axiomatisation of 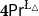 $\mathbf {4}\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}_\triangle }$ and establish faithful translations between it and
$\mathbf {4}\mathsf {Pr}^{{\mathsf {\unicode {x0141}}}_\triangle }$ and establish faithful translations between it and 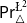 $\mathsf {Pr}^{\mathsf {\unicode {x0141}}^2}_\triangle$. We also show that the validity problem in all the logics is
$\mathsf {Pr}^{\mathsf {\unicode {x0141}}^2}_\triangle$. We also show that the validity problem in all the logics is 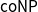 $\mathsf {coNP}$-complete.
$\mathsf {coNP}$-complete.
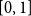
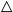
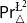
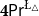
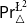
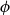
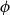
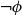
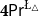
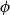
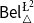
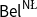
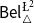
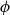
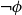
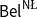
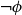
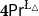
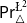
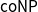
On calculating structural similarity metrics in population-based structural health monitoring
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 08 April 2025, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Principal types as partial involutions
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 08 April 2025, e8
-
- Article
- Export citation
Prior’s ideal language
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 08 April 2025, e7
-
- Article
- Export citation
On higher-order communication in ambient calculi
-
- Journal:
- Mathematical Structures in Computer Science / Volume 35 / 2025
- Published online by Cambridge University Press:
- 08 April 2025, e2
-
- Article
- Export citation
