Refine search
Actions for selected content:
49417 results in Computer Science
Drawing sound in space: Digital spatial notation as constitutive audiovisuality
-
- Journal:
- Organised Sound , First View
- Published online by Cambridge University Press:
- 24 February 2026, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Embedding Data into Instruments: An Ethical-Embodied Framework for Electroacoustic Practice
-
- Journal:
- Organised Sound , First View
- Published online by Cambridge University Press:
- 24 February 2026, pp. 1-10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Contemporary Notation Framework: Approaches, encoding and medium
-
- Journal:
- Organised Sound , First View
- Published online by Cambridge University Press:
- 24 February 2026, pp. 1-8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Axiom-based aggregation functions for calculating variety, novelty, quality and quantity of ideation results
-
- Journal:
- Design Science / Volume 12 / 2026
- Published online by Cambridge University Press:
- 23 February 2026, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How nations narrate quantum policy: A topic modeling approach to national quantum strategies
- Part of
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 23 February 2026, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Ordering of extreme order statistics among
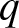 $q$-Weibull random variables
$q$-Weibull random variables
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 23 February 2026, pp. 1-24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The
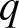 $q$-Weibull distribution, as a generalization of the Weibull distribution, plays an important role in the field of reliability theory, survival analysis, finance, engineering, medical science, etc. In contrast to the Weibull distribution, which is limited to describing monotonic hazard rate functions, the
$q$-Weibull distribution, as a generalization of the Weibull distribution, plays an important role in the field of reliability theory, survival analysis, finance, engineering, medical science, etc. In contrast to the Weibull distribution, which is limited to describing monotonic hazard rate functions, the 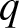 $q$-Weibull distribution offers the flexibility to model various behaviors of the hazard rate function, including unimodal, bathtub-shaped, monotonic (both increasing and decreasing), and constant. In this article, we investigated the stochastic comparison of extreme order statistics derived from independent, heterogeneous
$q$-Weibull distribution offers the flexibility to model various behaviors of the hazard rate function, including unimodal, bathtub-shaped, monotonic (both increasing and decreasing), and constant. In this article, we investigated the stochastic comparison of extreme order statistics derived from independent, heterogeneous 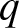 $q$-Weibull random variables using various stochastic orderings, including the usual stochastic order, hazard rate order, reversed hazard rate order, and likelihood ratio order. Some of these results are further extended to dependent setups by incorporating Archimedean copulas to model the dependence structure. Finally, we explored the behavior of extreme order statistics when the random variables are subjected to random shocks.
$q$-Weibull random variables using various stochastic orderings, including the usual stochastic order, hazard rate order, reversed hazard rate order, and likelihood ratio order. Some of these results are further extended to dependent setups by incorporating Archimedean copulas to model the dependence structure. Finally, we explored the behavior of extreme order statistics when the random variables are subjected to random shocks.
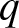
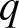
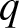
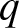
Embedded model form uncertainty quantification with measurement noise for Bayesian model calibration
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 23 February 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Towards common ground in notation for augmented instruments
-
- Journal:
- Organised Sound , First View
- Published online by Cambridge University Press:
- 23 February 2026, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Discovering the complexity of residual lifetimes of live components in the coherent system using cumulative residual extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 23 February 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper investigates the complexity of residual lifetimes of live components in coherent systems through the lens of cumulative residual extropy and its divergence-based extension, Jensen-cumulative residual extropy. Unlike classical reliability metrics that focus on system inactivity or mean residual life, our framework quantifies the hidden informational structure of components that remain alive at the system failure time. We derive closed-form expressions for the cumulative residual extropy of conditional residual lifetimes using system signatures and establish stochastic bounds and comparisons that highlight the impact of structural configuration. A novel divergence measure, the Jensen-cumulative residual extropy, is introduced to capture discrepancies between coherent systems and benchmark
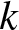 $k$-out-of-
$k$-out-of-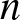 $n$ structures. Numerical illustrations with gamma-distributed lifetimes demonstrate the sensitivity of cumulative residual extropy and Jensen-cumulative residual extropy to redundancy patterns and dependence structures. Furthermore, by integrating cost considerations into the divergence framework, we provide a rigorous optimization scheme for selecting system signatures that jointly minimize informational complexity and economic expenditure. The proposed approach enriches the theoretical foundation of reliability analysis and offers practical guidelines for designing resilient, cost-effective, and information-efficient engineering systems.
$n$ structures. Numerical illustrations with gamma-distributed lifetimes demonstrate the sensitivity of cumulative residual extropy and Jensen-cumulative residual extropy to redundancy patterns and dependence structures. Furthermore, by integrating cost considerations into the divergence framework, we provide a rigorous optimization scheme for selecting system signatures that jointly minimize informational complexity and economic expenditure. The proposed approach enriches the theoretical foundation of reliability analysis and offers practical guidelines for designing resilient, cost-effective, and information-efficient engineering systems.

Introduction to Online Control
-
- Published online:
- 20 February 2026
- Print publication:
- 26 March 2026

Governing AI
- A Primer
-
- Published online:
- 20 February 2026
- Print publication:
- 19 February 2026
ROB volume 43 issue 12 Cover and Front matter
-
- Article
-
- You have access
- Export citation
MODAL DEFINABILITY IN KRIPKE’S THEORY OF TRUTH
- Part of
-
- Journal:
- The Review of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 20 February 2026, pp. 1-22
-
- Article
- Export citation
24 - Empirical Evidence about Individual Behavior in Games
- from Part VI - Individual Behavior In Strategic Interactions
-
-
- Book:
- One Hundred Years of Game Theory
- Published online:
- 03 March 2026
- Print publication:
- 19 February 2026, pp 260-275
-
- Chapter
- Export citation
Principal component analysis and K-means clustering of fuel–air mixing in gas turbine combustors
-
- Journal:
- Data-Centric Engineering / Volume 7 / 2026
- Published online by Cambridge University Press:
- 19 February 2026, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Part VII - Political Science
-
- Book:
- One Hundred Years of Game Theory
- Published online:
- 03 March 2026
- Print publication:
- 19 February 2026, pp 311-312
-
- Chapter
- Export citation
Part IV - Computer Science
-
- Book:
- One Hundred Years of Game Theory
- Published online:
- 03 March 2026
- Print publication:
- 19 February 2026, pp 119-120
-
- Chapter
- Export citation
Prologue
-
- Book:
- Governing AI
- Published online:
- 20 February 2026
- Print publication:
- 19 February 2026, pp 164-172
-
- Chapter
- Export citation
5 - Hyperarithmetic sets
-
- Book:
- Computable Structure Theory
- Published online:
- 30 January 2026
- Print publication:
- 19 February 2026, pp 69-84
-
- Chapter
- Export citation
