Refine search
Actions for selected content:
49417 results in Computer Science
A softgrowing robotic system for odor detection and classification
-
- Journal:
- Robotica , First View
- Published online by Cambridge University Press:
- 10 March 2026, pp. 1-29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Odor classification is essential in environmental monitoring, gas leak detection, and industrial safety. Although conventional mobile robotic platforms equipped with electronic noses offer advanced gas-sensing capabilities, their performance in confined or cluttered environments is often constrained by rigid structures and limited maneuverability. In this work, we present an olfactory softgrowing robot (oSGR) that integrates bio-inspired, growth-based locomotion with machine-learning (ML)-driven odor classification. Our system comprises a pressurized base enabling contact-free eversion and a custom motorized tip mount housing a multi-sensor array of four metal oxide TGS sensors (2600, 2602, 2611, and 2620) coupled with a passive aspirator for volatile organic compound (VOC) sampling. We provide detailed modeling, design, and structural characterization of the tip mount under multiple actuation configurations, and demonstrate the robot’s olfactory capability through experiments involving four VOCs – ethanol, methane, gin, and acetone. We evaluated two experimental modes: (i) in-transit and static sampling at fixed distances (
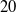 $20$,
$20$, 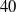 $40$, and
$40$, and 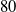 $80$ cm from the source), and (ii) continuous sampling during transit at speeds of
$80$ cm from the source), and (ii) continuous sampling during transit at speeds of 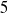 $5$ cm/s and
$5$ cm/s and 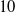 $10$ cm/s. The collected olfactory dataset was used to train twelve widely employed supervised ML classifiers in gas sensing, including k-Nearest Neighbors (kNN), Random Forest, and Linear Discriminant Analysis. The kNN classifier achieved the highest accuracy (99.88%), demonstrating strong robustness for the olfactory data. Our results highlight the potential of SGRs for contact-free, continuous, in-motion chemical sensing. This unique data acquisition approach reduces detection latency and energy consumption typically associated with conventional stop-and-sense strategies.
$10$ cm/s. The collected olfactory dataset was used to train twelve widely employed supervised ML classifiers in gas sensing, including k-Nearest Neighbors (kNN), Random Forest, and Linear Discriminant Analysis. The kNN classifier achieved the highest accuracy (99.88%), demonstrating strong robustness for the olfactory data. Our results highlight the potential of SGRs for contact-free, continuous, in-motion chemical sensing. This unique data acquisition approach reduces detection latency and energy consumption typically associated with conventional stop-and-sense strategies.
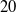
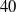
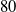
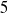
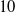
Multi-objective optimization of a dish parabolic concentrator with a parallel sun-tracking mechanism
-
- Journal:
- Robotica , First View
- Published online by Cambridge University Press:
- 10 March 2026, pp. 1-16
-
- Article
- Export citation
Trace reconstruction of matrices and hypermatrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 10 March 2026, pp. 1-19
-
- Article
- Export citation
-
A trace of a sequence is generated by deleting each bit of the sequence independently with a fixed probability. The well-studied trace reconstruction problem asks how many traces are required to reconstruct an unknown binary sequence with high probability. In this paper, we study the multidimensional version of this problem for matrices and hypermatrices, where a trace is generated by deleting each row/column of the matrix or each slice of the hypermatrix independently with a constant probability. Previously, Krishnamurthy, Mazumdar, McGregor and Pal showed that
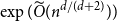 $\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown 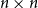 $n\times n$ matrix (for
$n\times n$ matrix (for 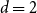 $d=2$) and any unknown
$d=2$) and any unknown 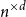 $n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around
$n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around 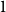 $1$, we improve this upper bound by showing that
$1$, we improve this upper bound by showing that 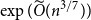 $\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown 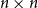 $n\times n$ matrix, and
$n\times n$ matrix, and 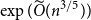 $\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown 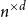 $n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from
$n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from 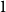 $1$ even as
$1$ even as 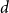 $d$ becomes very large.
$d$ becomes very large.
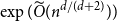
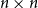
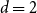
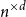
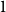
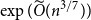
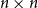
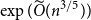
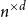
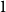
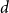
The illusion of the Web3 decentralization
-
- Journal:
- Data & Policy / Volume 8 / 2026
- Published online by Cambridge University Press:
- 09 March 2026, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Gentzen–Mints–Zucker duality
-
- Journal:
- Mathematical Structures in Computer Science / Volume 36 / 2026
- Published online by Cambridge University Press:
- 09 March 2026, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Linear logic and the Hilbert scheme
-
- Journal:
- Mathematical Structures in Computer Science / Volume 36 / 2026
- Published online by Cambridge University Press:
- 09 March 2026, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Design and experimental validation of an intention-controlled cable-driven soft robotic glove exoskeleton for assistance and rehabilitation
-
- Journal:
- Robotica , First View
- Published online by Cambridge University Press:
- 09 March 2026, pp. 1-29
-
- Article
- Export citation

Bandit Convex Optimisation
-
- Published online:
- 07 March 2026
- Print publication:
- 19 March 2026
ROB volume 44 issue 1 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Artificial intelligence across design thinking: a qualitative review
-
- Journal:
- Design Science / Volume 12 / 2026
- Published online by Cambridge University Press:
- 06 March 2026, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How do they stack up? Perceived communicative competence, foreign language anxiety, teacher support, and classroom environment in EFL learners’ willingness to communicate in MOOCs
-
- Journal:
- ReCALL , First View
- Published online by Cambridge University Press:
- 06 March 2026, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Trajectory planning for cable robot with pneumatic cylinder integration: direct collocation method
-
- Journal:
- Robotica , First View
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ITERATING REFLECTION OVER INTUITIONISTIC ARITHMETIC
-
- Journal:
- The Review of Symbolic Logic / Accepted manuscript
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-21
-
- Article
- Export citation
Day algebras
-
- Journal:
- Mathematical Structures in Computer Science / Volume 36 / 2026
- Published online by Cambridge University Press:
- 04 March 2026, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The largest subcritical component in inhomogeneous random graphs of preferential attachment type
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 04 March 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Categories for collection monads
-
- Journal:
- Mathematical Structures in Computer Science / Volume 36 / 2026
- Published online by Cambridge University Press:
- 04 March 2026, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

One Hundred Years of Game Theory
- A Nobel Symposium
-
- Published online:
- 03 March 2026
- Print publication:
- 19 February 2026
The open work and AI: Co-creation and haunting in text scores and inherent scores
-
- Journal:
- Organised Sound , First View
- Published online by Cambridge University Press:
- 03 March 2026, pp. 1-11
-
- Article
- Export citation
Sense of Place, Space and Belonging in Ainolnaim Azizol’s Electroacoustic Soundscape Bayu Nokturnal II
-
- Journal:
- Organised Sound , First View
- Published online by Cambridge University Press:
- 03 March 2026, pp. 1-12
-
- Article
- Export citation
Reassembling Russek’s Summermood: Revitalising Mexico’s electroacoustic legacy through modern performance
-
- Journal:
- Organised Sound , First View
- Published online by Cambridge University Press:
- 03 March 2026, pp. 1-7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
