Refine search
Actions for selected content:
49488 results in Computer Science
Comparative analysis of popular mobile robot roadmap path-planning methods
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
IS THERE A COUNTABLE OMEGA-UNIVERSAL LOGIC?
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 10 March 2025, pp. 963-970
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reversing the logic of generative AI alignment: a pragmatic approach for public interest
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 10 March 2025, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Impact of increased anthropogenic Amazon wildfires on Antarctic Sea ice melt via albedo reduction
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 10 March 2025, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This study shows the impact of black carbon (BC) aerosol atmospheric rivers (AAR) on the Antarctic Sea ice retreat. We detect that a higher number of BC AARs arrived in the Antarctic region due to increased anthropogenic wildfire activities in 2019 in the Amazon compared to 2018. Our analyses suggest that the BC AARs led to a reduction in the sea ice albedo, increased the amount of sunlight absorbed at the surface, and a significant reduction of sea ice over the Weddell, Ross Sea (Ross), and Indian Ocean (IO) regions in 2019. The Weddell region experienced the largest amount of sea ice retreat (
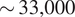 $ \sim \mathrm{33,000} $ km2) during the presence of BC AARs as compared to
$ \sim \mathrm{33,000} $ km2) during the presence of BC AARs as compared to 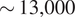 $ \sim \mathrm{13,000} $ km2 during non-BC days. We used a suite of data science techniques, including random forest, elastic net regression, matrix profile, canonical correlations, and causal discovery analyses, to discover the effects and validate them. Random forest, elastic net regression, and causal discovery analyses show that the shortwave upward radiative flux or the reflected sunlight, temperature, and longwave upward energy from the earth are the most important features that affect sea ice extent. Canonical correlation analysis confirms that aerosol optical depth is negatively correlated with albedo, positively correlated with shortwave energy absorbed at the surface, and negatively correlated with Sea Ice Extent. The relationship is stronger in 2019 than in 2018. This study also employs the matrix profile and convolution operation of the Convolution Neural Network (CNN) to detect anomalous events in sea ice loss. These methods show that a higher amount of anomalous melting events were detected over the Weddell and Ross regions.
$ \sim \mathrm{13,000} $ km2 during non-BC days. We used a suite of data science techniques, including random forest, elastic net regression, matrix profile, canonical correlations, and causal discovery analyses, to discover the effects and validate them. Random forest, elastic net regression, and causal discovery analyses show that the shortwave upward radiative flux or the reflected sunlight, temperature, and longwave upward energy from the earth are the most important features that affect sea ice extent. Canonical correlation analysis confirms that aerosol optical depth is negatively correlated with albedo, positively correlated with shortwave energy absorbed at the surface, and negatively correlated with Sea Ice Extent. The relationship is stronger in 2019 than in 2018. This study also employs the matrix profile and convolution operation of the Convolution Neural Network (CNN) to detect anomalous events in sea ice loss. These methods show that a higher amount of anomalous melting events were detected over the Weddell and Ross regions.
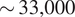
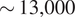
Uncertainty quantification in tree structure and polynomial regression algorithms toward material indices prediction
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 10 March 2025, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Detection avoidance techniques for large language models
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 10 March 2025, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hitting times on the lollipop graph
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 07 March 2025, pp. 486-519
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bayesian adaptive trials for social policy
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 05 March 2025, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Statistical constraints on climate model parameters using a scalable cloud-based inference framework – CORRIGENDUM
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 05 March 2025, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bayesian causal discovery for policy decision making
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 04 March 2025, e26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An interacting Wasserstein gradient flow strategy to robust Bayesian inference for application to decision-making in engineering
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 04 March 2025, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An energy-based numerical continuation approach for quasi-static mechanical manipulation
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 04 March 2025, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Natural VR modeling: a viable alternative to freehand sketching for preliminary design?
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 03 March 2025, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A framework for scalable ambient air pollution concentration estimation
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 03 March 2025, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Foreword
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 10 / November 2024
- Published online by Cambridge University Press:
- 03 March 2025, p. 1054
-
- Article
-
- You have access
- HTML
- Export citation
Unveiling founder archetypes: the effect of distinct entrepreneurial traits on resource accuracy
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 03 March 2025, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
RSL volume 18 issue 1 Cover and Back matter
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 16 April 2025, pp. b1-b2
- Print publication:
- March 2025
-
- Article
-
- You have access
- Export citation
RSL volume 18 issue 1 Cover and Front matter
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 16 April 2025, pp. f1-f4
- Print publication:
- March 2025
-
- Article
-
- You have access
- Export citation
IMAGINATION, MEREOTOPOLOGY, AND TOPIC EXPANSION
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 07 April 2025, pp. 28-51
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analyzing climate scenarios using dynamic mode decomposition with control
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 28 February 2025, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
