Refine search
Actions for selected content:
49488 results in Computer Science
The number of overlapping customers in Erlang-A queues: an asymptotic approach
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 21 February 2025, pp. 344-369
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Active learning for regression in engineering populations: a risk-informed approach
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 21 February 2025, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A negative charge at position D+5 of Motif A is critical for function of the major facilitator superfamily multidrug/H+ antiporter MdtM’ – RETRACTION
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 21 February 2025, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interacting with ChatGPT in essay writing: A study of L2 learners’ task motivation
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Graph connectivity with fixed endpoints in the random-connection model
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 21 February 2025, pp. 370-396
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the count of subgraphs with an arbitrary configuration of endpoints in the random-connection model based on a Poisson point process on
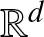 ${\mathord{\mathbb R}}^d$. We present combinatorial expressions for the computation of the cumulants and moments of all orders of such subgraph counts, which allow us to estimate the growth of cumulants as the intensity of the underlying Poisson point process goes to infinity. As a consequence, we obtain a central limit theorem with explicit convergence rates under the Kolmogorov distance and connectivity bounds. Numerical examples are presented using a computer code in SageMath for the closed-form computation of cumulants of any order, for any type of connected subgraph, and for any configuration of endpoints in any dimension
${\mathord{\mathbb R}}^d$. We present combinatorial expressions for the computation of the cumulants and moments of all orders of such subgraph counts, which allow us to estimate the growth of cumulants as the intensity of the underlying Poisson point process goes to infinity. As a consequence, we obtain a central limit theorem with explicit convergence rates under the Kolmogorov distance and connectivity bounds. Numerical examples are presented using a computer code in SageMath for the closed-form computation of cumulants of any order, for any type of connected subgraph, and for any configuration of endpoints in any dimension 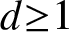 $d{\geq} 1$. In particular, graph connectivity estimates, Gram–Charlier expansions for density estimation, and correlation estimates for joint subgraph counting are obtained.
$d{\geq} 1$. In particular, graph connectivity estimates, Gram–Charlier expansions for density estimation, and correlation estimates for joint subgraph counting are obtained.
Competition between protons and substrate for binding to the major facilitator superfamily multidrug/H+ antiporter MdtM’ – RETRACTION
-
- Journal:
- Experimental Results / Volume 4 / 2023
- Published online by Cambridge University Press:
- 21 February 2025, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Count on Me: Moral Language in Social Media and Policy Discourse during the Ukraine-Russia Conflict
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 21 February 2025, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Uneven progress: Analyzing the factors behind digital technology adoption rates in Sub-Saharan Africa (SSA)
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 21 February 2025, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
8 - E-Commerce Platforms as Product Merchants and Sellers
- from Part II - The Implications of Emerging Product Design and Business Models
-
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp 171-194
-
- Chapter
- Export citation
9 - 3D Printing
- from Part II - The Implications of Emerging Product Design and Business Models
-
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp 195-214
-
- Chapter
- Export citation
6 - Quantum Privacy
- from Part I - Contemporary Technological Developments
-
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp 128-147
-
- Chapter
- Export citation
10 - The Right to Repair, Intellectual Property, Exhaustion, and Preemption
- from Part II - The Implications of Emerging Product Design and Business Models
-
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp 215-229
-
- Chapter
- Export citation
Risk management in the era of data-centric engineering
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 20 February 2025, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
2 - The Challenges of Technological Property
- from Part I - Contemporary Technological Developments
-
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp 34-50
-
- Chapter
- Export citation
Contributors
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp xv-xxii
-
- Chapter
- Export citation
12 - Ending Smart Data Enclosures
- from Part II - The Implications of Emerging Product Design and Business Models
-
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp 258-283
-
- Chapter
- Export citation
Part I - Contemporary Technological Developments
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp 1-168
-
- Chapter
- Export citation
1 - Non-fungible Tokens in Commercial Transactions
- from Part I - Contemporary Technological Developments
-
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp 3-33
-
- Chapter
- Export citation
Index
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp 457-480
-
- Chapter
- Export citation
