Refine search
Actions for selected content:
49488 results in Computer Science
Remembering/imagining: Shona Illingworth’s time present and Trinh-T Minh-Ha’s forgetting Vietnam
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 4 / 2025
- Published online by Cambridge University Press:
- 28 February 2025, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
OpenForest: a data catalog for machine learning in forest monitoring
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 27 February 2025, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data technologies and analytics for policy and governance: a landscape review
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 27 February 2025, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
GenFormer: a deep-learning-based approach for generating multivariate stochastic processes
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 27 February 2025, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ChatGPT as an inventor: eliciting the strengths and weaknesses of current large language models against humans in engineering design
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How much is in a square? Calculating functional programs with squares
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 35 / 2026
- Published online by Cambridge University Press:
- 26 February 2025, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Experience in teaching functional programming (FP) on a relational basis has led the author to focus on a graphical style of expression and reasoning in which a geometric construct shines: the (semi) commutative square. In the classroom this is termed the “magic square” (MS), since virtually everything that we do in logic, FP, database modeling, formal semantics and so on fits in some MS geometry. The sides of each magic square are binary relations and the square itself is a comparison of two paths, each involving two sides. MSs compose and have a number of useful properties. Among several examples given in the paper ranging over different application domains, free-theorem MSs are shown to be particularly elegant and productive. Helped by a little bit of Galois connections, a generic, induction-free theory for
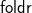 ${\mathsf{foldr}}$ and
${\mathsf{foldr}}$ and 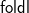 $\mathsf{foldl}$ is given, showing in particular that
$\mathsf{foldl}$ is given, showing in particular that  ${\mathsf{foldl} \, {{s}}{}\mathrel{=}\mathsf{foldr}{({flip} \unicode{x005F}{s})}{}}$ holds under conditions milder than usually advocated.
${\mathsf{foldl} \, {{s}}{}\mathrel{=}\mathsf{foldr}{({flip} \unicode{x005F}{s})}{}}$ holds under conditions milder than usually advocated.
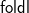

CUT-FREE SEQUENT CALCULI FOR THE PROVABILITY LOGIC D
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 2 / June 2025
- Published online by Cambridge University Press:
- 26 February 2025, pp. 505-526
- Print publication:
- June 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We say that a Kripke model is a GL-model (Gödel and Löb model) if the accessibility relation
 $\prec $ is transitive and converse well-founded. We say that a Kripke model is a D-model if it is obtained by attaching infinitely many worlds
$\prec $ is transitive and converse well-founded. We say that a Kripke model is a D-model if it is obtained by attaching infinitely many worlds  $t_1, t_2, \ldots $, and
$t_1, t_2, \ldots $, and  $t_\omega $ to a world
$t_\omega $ to a world  $t_0$ of a GL-model so that
$t_0$ of a GL-model so that  $t_0 \succ t_1 \succ t_2 \succ \cdots \succ t_\omega $. A non-normal modal logic
$t_0 \succ t_1 \succ t_2 \succ \cdots \succ t_\omega $. A non-normal modal logic  $\mathbf {D}$, which was studied by Beklemishev [3], is characterized as follows. A formula
$\mathbf {D}$, which was studied by Beklemishev [3], is characterized as follows. A formula  $\varphi $ is a theorem of
$\varphi $ is a theorem of  $\mathbf {D}$ if and only if
$\mathbf {D}$ if and only if  $\varphi $ is true at
$\varphi $ is true at  $t_\omega $ in any D-model.
$t_\omega $ in any D-model.  $\mathbf {D}$ is an intermediate logic between the provability logics
$\mathbf {D}$ is an intermediate logic between the provability logics  $\mathbf {GL}$ and
$\mathbf {GL}$ and  $\mathbf {S}$. A Hilbert-style proof system for
$\mathbf {S}$. A Hilbert-style proof system for  $\mathbf {D}$ is known, but there has been no sequent calculus. In this paper, we establish two sequent calculi for
$\mathbf {D}$ is known, but there has been no sequent calculus. In this paper, we establish two sequent calculi for  $\mathbf {D}$, and show the cut-elimination theorem. We also introduce new Hilbert-style systems for
$\mathbf {D}$, and show the cut-elimination theorem. We also introduce new Hilbert-style systems for  $\mathbf {D}$ by interpreting the sequent calculi. Moreover, we show that D-models can be defined using an arbitrary limit ordinal as well as
$\mathbf {D}$ by interpreting the sequent calculi. Moreover, we show that D-models can be defined using an arbitrary limit ordinal as well as  $\omega $. Finally, we show a general result as follows. Let X and
$\omega $. Finally, we show a general result as follows. Let X and  $X^+$ be arbitrary modal logics. If the relationship between semantics of X and semantics of
$X^+$ be arbitrary modal logics. If the relationship between semantics of X and semantics of  $X^+$ is equal to that of
$X^+$ is equal to that of  $\mathbf {GL}$ and
$\mathbf {GL}$ and  $\mathbf {D}$, then
$\mathbf {D}$, then  $X^+$ can be axiomatized based on X in the same way as the new axiomatization of
$X^+$ can be axiomatized based on X in the same way as the new axiomatization of  $\mathbf {D}$ based on
$\mathbf {D}$ based on  $\mathbf {GL}$.
$\mathbf {GL}$.
























Extropy-based dynamic cumulative residual inaccuracy measure: properties and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 26 February 2025, pp. 461-485
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Recursive subtyping for all
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 35 / 2026
- Published online by Cambridge University Press:
- 26 February 2025, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Recursive types and bounded quantification are prominent features in many modern programming languages, such as Java, C#, Scala, or TypeScript. Unfortunately, the interaction between recursive types, bounded quantification, and subtyping has shown to be problematic in the past. Consequently, defining a simple foundational calculus that combines those features and has desirable properties, such as decidability, transitivity of subtyping, conservativity, and a sound and complete algorithmic formulation, has been a long-time challenge.
This paper shows how to extend
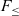 $F_{\le}$ with iso-recursive types in a new calculus called
$F_{\le}$ with iso-recursive types in a new calculus called 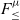 $F_{\le}^{\mu}$.
$F_{\le}^{\mu}$. 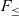 $F_{\le}$ is a well-known polymorphic calculus with bounded quantification. In
$F_{\le}$ is a well-known polymorphic calculus with bounded quantification. In 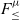 $F_{\le}^{\mu}$, we add iso-recursive types and correspondingly extend the subtyping relation with iso-recursive subtyping using the recently proposed nominal unfolding rules. In addition, we use so-called structural folding/unfolding rules for typing iso-recursive expressions, inspired by the structural unfolding rule proposed by Abadi et al. (1996). The structural rules add expressive power to the more conventional folding/unfolding rules in the literature, and they enable additional applications. We present several results, including: type soundness; transitivity; the conservativity of
$F_{\le}^{\mu}$, we add iso-recursive types and correspondingly extend the subtyping relation with iso-recursive subtyping using the recently proposed nominal unfolding rules. In addition, we use so-called structural folding/unfolding rules for typing iso-recursive expressions, inspired by the structural unfolding rule proposed by Abadi et al. (1996). The structural rules add expressive power to the more conventional folding/unfolding rules in the literature, and they enable additional applications. We present several results, including: type soundness; transitivity; the conservativity of 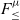 $F_{\le}^{\mu}$ over
$F_{\le}^{\mu}$ over 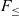 $F_{\le}$; and a sound and complete algorithmic formulation of
$F_{\le}$; and a sound and complete algorithmic formulation of 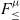 $F_{\le}^{\mu}$. We study two variants of
$F_{\le}^{\mu}$. We study two variants of 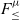 $F_{\le}^{\mu}$. The first one uses an extension of the
$F_{\le}^{\mu}$. The first one uses an extension of the 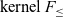 $\textrm{kernel}~F_{\le}$ (a well-known decidable variant of
$\textrm{kernel}~F_{\le}$ (a well-known decidable variant of 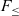 $F_{\le}$). This extension accepts equivalent rather than equal bounds and is shown to preserve decidable subtyping. The second variant employs the
$F_{\le}$). This extension accepts equivalent rather than equal bounds and is shown to preserve decidable subtyping. The second variant employs the  $\textrm{full}~F_{\le}$ rule for bounded quantification and has undecidable subtyping. Moreover, we also study an extension of the kernel version of
$\textrm{full}~F_{\le}$ rule for bounded quantification and has undecidable subtyping. Moreover, we also study an extension of the kernel version of 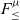 $F_{\le}^{\mu}$, called
$F_{\le}^{\mu}$, called 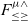 $F_{\le\ge}^{\mu\wedge}$, with a form of intersection types and lower bounded quantification. All the properties from the kernel version of
$F_{\le\ge}^{\mu\wedge}$, with a form of intersection types and lower bounded quantification. All the properties from the kernel version of 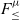 $F_{\le}^{\mu}$ are preserved in
$F_{\le}^{\mu}$ are preserved in 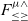 $F_{\le\ge}^{\mu\wedge}$. All the results in this paper have been formalized in the Coq theorem prover.
$F_{\le\ge}^{\mu\wedge}$. All the results in this paper have been formalized in the Coq theorem prover.
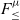
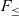
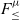
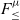
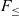
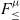
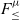
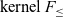
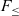

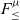
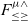
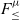
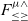
A GENUINELY UNTYPED EXPLANATION OF COMMON BELIEF AND KNOWLEDGE
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 18 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 25 February 2025, pp. 160-185
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Some generalized information and divergence generating functions: properties, estimation, validation, and applications
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 25 February 2025, pp. 397-430
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reliability analysis of a K-out-of-N system with random rate of repair
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 25 February 2025, pp. 431-460
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
When forecasting and foresight meet data and innovation: toward a taxonomy of anticipatory methods for migration policy
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 25 February 2025, e24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AI-driven design exploration: Utilizing brand logos as an inspiration source for architectural design
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Crisis-prompted online language teaching: a qualitative inquiry into autonomy among teachers in refugee settings
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Kinematic design and analysis of a novel overconstraint walking mechanism
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Machine Learning with Python
- Principles and Practical Techniques
-
- Published online:
- 22 February 2025
- Print publication:
- 26 March 2026
-
- Textbook
- Export citation
