Refine search
Actions for selected content:
49488 results in Computer Science
Tables
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp xiii-xiv
-
- Chapter
- Export citation
Preface
-
- Book:
- The Cambridge Handbook of Emerging Issues at the Intersection of Commercial Law and Technology
- Published online:
- 08 February 2025
- Print publication:
- 20 February 2025, pp xxiii-xxiv
-
- Chapter
- Export citation
Migrants’ and refugees’ digital literacies in life and language learning
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The mean residual life at random age and its connection to variability measures
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 3 / July 2025
- Published online by Cambridge University Press:
- 19 February 2025, pp. 326-343
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider a nonnegative random variable T representing the lifetime of a system. We discuss the residual lifetime
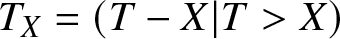 $T_X=(T-X|T \gt X)$, where X denotes the random age of the system. We also discuss the mean residual life (MRL) of T at the random time X. It is shown that the MRL at random age (MRLR) is closely related to some well-known variability measures. In particular, we show that the MRLR can be considered a generalization of Gini’s mean difference (GMD). Under the proportional hazards model, we show that the MRLR gives the extended GMD and the extended cumulative residual entropy as special cases. Then, we provide a decomposition result indicating that the MRLR has a covariance representation. Some comparison results are also established for the MRLs of two systems at random ages.
$T_X=(T-X|T \gt X)$, where X denotes the random age of the system. We also discuss the mean residual life (MRL) of T at the random time X. It is shown that the MRL at random age (MRLR) is closely related to some well-known variability measures. In particular, we show that the MRLR can be considered a generalization of Gini’s mean difference (GMD). Under the proportional hazards model, we show that the MRLR gives the extended GMD and the extended cumulative residual entropy as special cases. Then, we provide a decomposition result indicating that the MRLR has a covariance representation. Some comparison results are also established for the MRLs of two systems at random ages.
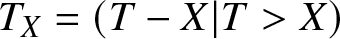
Integrating collaborative digital multimodal tasks in Spanish as a second language course
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
From counting stations to city-wide estimates: data-driven bicycle volume extrapolation
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 18 February 2025, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis of National Cybersecurity Strategies of G20: objectives, latent themes, latest trends and comparisons
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 18 February 2025, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Fostering public trust in national health data platforms: key considerations for public involvement activities for England and Switzerland
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The REDATAM format and its challenges for data access and information creation in public policy
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Invisible data in night-time governance: addressing policy gaps and building a digital rights framework for cities after dark
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Semi-parametric estimation of system reliability for multicomponent stress-strength model under hierarchical Archimedean copulas
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 2 / April 2025
- Published online by Cambridge University Press:
- 17 February 2025, pp. 278-308
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Blend up: empowering LESLLA learners through blended learning
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
State-linked manipulated media in the time of Covid-19: a look at Iran
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The role of carbonate equilibrium in scale formation of calcium carbonate in a power plant open recirculating system
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 17 February 2025, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Advancing early warning mechanisms: an augmented intelligence-driven model for predicting multidimensional vulnerability levels in Afghanistan
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 14 February 2025, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Direct Encoding of Declare Constraints in ASP
-
- Journal:
- Theory and Practice of Logic Programming / Volume 25 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 14 February 2025, pp. 92-131
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Answer set programming (ASP), a well-known declarative logic programming paradigm, has recently found practical application in Process Mining. In particular, ASP has been used to model tasks involving declarative specifications of business processes. In this area,
Declare stands out as the most widely adopted declarative process modeling language, offering a means to model processes through sets of constraints valid traces must satisfy, that can be expressed in linear temporal logic over finite traces (LTL $_{\text {f}}$). Existing ASP-based solutions encode
$_{\text {f}}$). Existing ASP-based solutions encode Declare constraints by modeling the corresponding LTL $_{\text {f}}$ formula or its equivalent automaton which can be obtained using established techniques. In this paper, we introduce a novel encoding for
$_{\text {f}}$ formula or its equivalent automaton which can be obtained using established techniques. In this paper, we introduce a novel encoding for Declare constraints that directly models their semantics as ASP rules, eliminating the need for intermediate representations. We assess the effectiveness of this novel approach on two Process Mining tasks by comparing it with alternative ASP encodings and a Python library forDeclare .


13 - Artificial Intelligence and Education
- from Part III - AI across Sectors
-
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 261-282
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
10 - AI and Consumer Protection
- from Part II - AI, Law and Policy
-
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 192-210
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
