Refine search
Actions for selected content:
49488 results in Computer Science
4 - Fairness and Artificial Intelligence
- from Part I - AI, Ethics and Philosophy
-
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 79-100
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Contributors
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp xiii-xxiv
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
20 - Artificial Intelligence and Armed Conflicts
- from Part III - AI across Sectors
-
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 411-428
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Figures and Tables
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp xi-xii
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
19 - The Use of Algorithmic Systems by Public Administrations
- from Part III - AI across Sectors
-
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 383-410
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
9 - Artificial Intelligence and Competition Law
- from Part II - AI, Law and Policy
-
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 174-191
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
16 - Artificial Intelligence and Financial Services
- from Part III - AI across Sectors
-
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 322-338
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Dedication
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp v-vi
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
18 - Legal, Ethical, and Social Issues of AI and Law Enforcement in Europe
- from Part III - AI across Sectors
-
-
- Book:
- The Cambridge Handbook of the Law, Ethics and Policy of Artificial Intelligence
- Published online:
- 06 February 2025
- Print publication:
- 13 February 2025, pp 367-382
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
Simulating the air quality impact of prescribed fires using graph neural network-based PM2.5 forecasts
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 12 February 2025, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Simulation of global sea surface temperature maps using Pix2Pix GAN
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 12 February 2025, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A conceptual framework for designing human-centered building-occupant interactions to enhance user experience in specific-purpose buildings
-
- Journal:
- Design Science / Volume 11 / 2025
- Published online by Cambridge University Press:
- 11 February 2025, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Preface: Advances in Homotopy Type Theory
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 9 / October 2024
- Published online by Cambridge University Press:
- 11 February 2025, pp. 892-893
-
- Article
-
- You have access
- HTML
- Export citation
Centrality and social domains: The role of support, conflict, and ambivalence in the perception of linguistic similarity
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The philosophical foundations of digital twinning
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hydrogen reaction rate modeling based on convolutional neural network for large eddy simulation
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This article establishes a data-driven modeling framework for lean hydrogen (
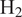 $ {\mathrm{H}}_2 $)-air reaction rates for the Large Eddy Simulation (LES) of turbulent reactive flows. This is particularly challenging since
$ {\mathrm{H}}_2 $)-air reaction rates for the Large Eddy Simulation (LES) of turbulent reactive flows. This is particularly challenging since 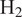 $ {\mathrm{H}}_2 $ molecules diffuse much faster than heat, leading to large variations in burning rates, thermodiffusive instabilities at the subfilter scale, and complex turbulence-chemistry interactions. Our data-driven approach leverages a Convolutional Neural Network (CNN), trained to approximate filtered burning rates from emulated LES data. First, five different lean premixed turbulent
$ {\mathrm{H}}_2 $ molecules diffuse much faster than heat, leading to large variations in burning rates, thermodiffusive instabilities at the subfilter scale, and complex turbulence-chemistry interactions. Our data-driven approach leverages a Convolutional Neural Network (CNN), trained to approximate filtered burning rates from emulated LES data. First, five different lean premixed turbulent 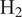 $ {\mathrm{H}}_2 $-air flame Direct Numerical Simulations (DNSs) are computed each with a unique global equivalence ratio. Second, DNS snapshots are filtered and downsampled to emulate LES data. Third, a CNN is trained to approximate the filtered burning rates as a function of LES scalar quantities: progress variable, local equivalence ratio, and flame thickening due to filtering. Finally, the performances of the CNN model are assessed on test solutions never seen during training. The model retrieves burning rates with very high accuracy. It is also tested on two filter and downsampling parameters and two global equivalence ratios between those used during training. For these interpolation cases, the model approximates burning rates with low error even though the cases were not included in the training dataset. This a priori study shows that the proposed data-driven machine learning framework is able to address the challenge of modeling lean premixed
$ {\mathrm{H}}_2 $-air flame Direct Numerical Simulations (DNSs) are computed each with a unique global equivalence ratio. Second, DNS snapshots are filtered and downsampled to emulate LES data. Third, a CNN is trained to approximate the filtered burning rates as a function of LES scalar quantities: progress variable, local equivalence ratio, and flame thickening due to filtering. Finally, the performances of the CNN model are assessed on test solutions never seen during training. The model retrieves burning rates with very high accuracy. It is also tested on two filter and downsampling parameters and two global equivalence ratios between those used during training. For these interpolation cases, the model approximates burning rates with low error even though the cases were not included in the training dataset. This a priori study shows that the proposed data-driven machine learning framework is able to address the challenge of modeling lean premixed 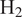 $ {\mathrm{H}}_2 $-air burning rates. It paves the way for a new modeling paradigm for the simulation of carbon-free hydrogen combustion systems.
$ {\mathrm{H}}_2 $-air burning rates. It paves the way for a new modeling paradigm for the simulation of carbon-free hydrogen combustion systems.
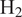
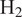
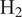
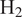
Case studies of AI policy development in Africa
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Causal temporal reasoning for Markov decision processes
-
- Journal:
- Research Directions: Cyber-Physical Systems / Volume 3 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unsupervised clustering identifies thermohaline staircases in the Canada Basin of the Arctic Ocean – CORRIGENDUM
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 10 February 2025, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
