Refine search
Actions for selected content:
49488 results in Computer Science
Task priority-based redundancy resolution of a 20 DoFs humanoid robot for object pick and place with minimum energy and dynamic balance
-
- Article
- Export citation
-
Humanoid robots are highly redundant, and finding whole-body optimal trajectories for various tasks is very complex. This paper proposes a method to find an energy-optimal, dynamically balanced, and collision-free trajectory of the 20 degrees of freedom humanoid robot in pick and place application. The task of pick and place is divided into three subtasks using the Pseudoinverse Jacobian method of redundancy resolution. The three subtasks are end effector trajectory represented by
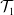 $\mathcal {T}_1$, hip trajectory represented by
$\mathcal {T}_1$, hip trajectory represented by 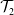 $\mathcal {T}_2$, and maximizing the manipulability represented by
$\mathcal {T}_2$, and maximizing the manipulability represented by 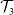 $\mathcal {T}_3$. The Pseudoinverse Jacobian method is coupled with particle swarm optimization (PSO) to find the optimal trajectories. The main contribution of this paper is the decomposition of the whole-body task of the humanoid robot into three distinct subtasks to find energy-optimal, dynamically balanced, and obstacle-free trajectories. The concept of virtual surface is used to avoid dragging objects on the table surface. The problem is optimized with Particle Swarm Optimization. Simulations were conducted to pick up and place objects from a table and constrained spaces like a drawer. The results show that the robot can pick and place objects from defined locations on the table.
$\mathcal {T}_3$. The Pseudoinverse Jacobian method is coupled with particle swarm optimization (PSO) to find the optimal trajectories. The main contribution of this paper is the decomposition of the whole-body task of the humanoid robot into three distinct subtasks to find energy-optimal, dynamically balanced, and obstacle-free trajectories. The concept of virtual surface is used to avoid dragging objects on the table surface. The problem is optimized with Particle Swarm Optimization. Simulations were conducted to pick up and place objects from a table and constrained spaces like a drawer. The results show that the robot can pick and place objects from defined locations on the table.
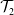
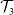
Copyright page
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp iv-iv
-
- Chapter
- Export citation
8 - Personal Reflections on the Journey
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp 119-126
-
- Chapter
- Export citation
Index
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp 141-144
-
- Chapter
- Export citation
Contents
-
- Book:
- Session Types
- Published online:
- 12 June 2025
- Print publication:
- 27 March 2025, pp v-viii
-
- Chapter
- Export citation
9 - Propositions as Sessions
-
- Book:
- Session Types
- Published online:
- 12 June 2025
- Print publication:
- 27 March 2025, pp 197-226
-
- Chapter
- Export citation
References
-
- Book:
- Session Types
- Published online:
- 12 June 2025
- Print publication:
- 27 March 2025, pp 227-231
-
- Chapter
- Export citation
Bibliography
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp 137-140
-
- Chapter
- Export citation
8 - Linear Pi Calculus with Values
-
- Book:
- Session Types
- Published online:
- 12 June 2025
- Print publication:
- 27 March 2025, pp 176-196
-
- Chapter
- Export citation
3 - Who – and What – Should Drive Decision-Making?
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp 41-56
-
- Chapter
- Export citation
Reviews
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp ii-ii
-
- Chapter
- Export citation
1 - The Pitfalls, Promises, and Challenges of Data
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp 1-18
-
- Chapter
- Export citation
4 - Sharing
-
- Book:
- Session Types
- Published online:
- 12 June 2025
- Print publication:
- 27 March 2025, pp 72-98
-
- Chapter
- Export citation
2 - A Confluence of Fields
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp 19-40
-
- Chapter
- Export citation
Preface
-
- Book:
- Session Types
- Published online:
- 12 June 2025
- Print publication:
- 27 March 2025, pp ix-xii
-
- Chapter
- Export citation
4 - A Transdiscipline Is Born
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp 57-72
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Data, Systems, and Society
- Published online:
- 24 March 2025
- Print publication:
- 27 March 2025, pp 127-136
-
- Chapter
- Export citation
On the effectiveness of neural operators at zero-shot weather downscaling
- Part of
-
- Journal:
- Environmental Data Science / Volume 4 / 2025
- Published online by Cambridge University Press:
- 27 March 2025, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
