Refine search
Actions for selected content:
49487 results in Computer Science
Appendix C - A Catalogue of 3-Polygraphs
- from Appendices
-
- Book:
- Polygraphs: From Rewriting to Higher Categories
- Published online:
- 18 March 2025
- Print publication:
- 03 April 2025, pp 513-571
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Verification, Validation, and Uncertainty Quantification in Scientific Computing
- Published online:
- 22 March 2025
- Print publication:
- 03 April 2025, pp 1-18
-
- Chapter
- Export citation
Automated extraction of discourse networks from large volumes of media data
- Part of
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 02 April 2025, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
“Doing Peace”: Conceptualizing relational peace through interactions and networks in a digitalized world
- Part of
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 02 April 2025, e34
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Baschet’s Voice Leaf: The voice wrapped in the sculptural leaf
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 07 April 2025, pp. 53-57
- Print publication:
- April 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Bridging Gaps in Black Music Research: A conversation on experimental sound by the BMRU
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 02 April 2025, pp. 6-14
- Print publication:
- April 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Editorial: Experimental sound from the Black and South Asian diaspora
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 25 July 2025, pp. 1-5
- Print publication:
- April 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Soundscapes of Papua: Cultural-based pedagogical approach through electroacoustic music
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 11 April 2025, pp. 32-40
- Print publication:
- April 2025
-
- Article
- Export citation
A Sonic Indofuturism
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 02 April 2025, pp. 15-23
- Print publication:
- April 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Electroacoustic Confessional: Confronting one’s artistic past
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 07 May 2025, pp. 41-52
- Print publication:
- April 2025
-
- Article
- Export citation
Investigating the Physically Hidden: Auditory-based illusions for sound installations
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 30 June 2025, pp. 68-80
- Print publication:
- April 2025
-
- Article
- Export citation
Small Gestures: Generating radical sonic futures in an algorithmic world
-
- Journal:
- Organised Sound / Volume 30 / Issue 1 / April 2025
- Published online by Cambridge University Press:
- 19 May 2025, pp. 24-31
- Print publication:
- April 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On multivariate contribution measures of systemic risk with applications in cryptocurrency market
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 4 / October 2025
- Published online by Cambridge University Press:
- 31 March 2025, pp. 551-578
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Internet of Things and hybrid models-based interpretation systems for surface roughness estimation – CORRIGENDUM
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Improve generalization for neural visual-SLAM with Bayes online learning
-
- Article
- Export citation
-
Among various deep learning-based SLAM systems, many exhibit low accuracy and inadequate generalization on non-training datasets. The deficiency in generalization ability can result in significant errors within SLAM systems during real-world applications, particularly in environments that diverge markedly from those represented in the training set. This paper presents a methodology to enhance the generalization capabilities of deep learning SLAM systems. It leverages their superior performance in feature extraction and introduces Exponential Moving Average (EMA) and Bayes online learning to improve generalization and localization accuracy in varied scenarios. Experimental validation, utilizing Absolute Trajectory Error (ATE) metrics on the dataset, has been conducted. The results demonstrate that this method effectively reduces errors by
 $20\%$ on the EuRoC dataset and by
$20\%$ on the EuRoC dataset and by 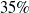 $35\%$ on the TUM dataset, respectively.
$35\%$ on the TUM dataset, respectively.