Refine search
Actions for selected content:
49522 results in Computer Science
Almost exact recovery in noisy semi-supervised learning
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 11 November 2024, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reinforcement actor-critic learning as a rehearsal in MicroRTS
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 39 / 2024
- Published online by Cambridge University Press:
- 08 November 2024, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unmasking the role of remote sensors in comfort, energy, and demand response
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 08 November 2024, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Groupoidal realizability for intensional type theory
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 9 / October 2024
- Published online by Cambridge University Press:
- 08 November 2024, pp. 911-944
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data-driven decarbonization framework with machine learning
- Part of
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 08 November 2024, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal approximate minimization of one-letter weighted finite automata
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 8 / September 2024
- Published online by Cambridge University Press:
- 08 November 2024, pp. 807-833
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we study the approximate minimization problem of weighted finite automata (WFAs): to compute the best possible approximation of a WFA given a bound on the number of states. By reformulating the problem in terms of Hankel matrices, we leverage classical results on the approximation of Hankel operators, namely the celebrated Adamyan-Arov-Krein (AAK) theory. We solve the optimal spectral-norm approximate minimization problem for irredundant WFAs with real weights, defined over a one-letter alphabet. We present a theoretical analysis based on AAK theory and bounds on the quality of the approximation in the spectral norm and
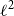 $\ell ^2$ norm. Moreover, we provide a closed-form solution, and an algorithm, to compute the optimal approximation of a given size in polynomial time.
$\ell ^2$ norm. Moreover, we provide a closed-form solution, and an algorithm, to compute the optimal approximation of a given size in polynomial time.
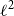
FloodGNN-GRU: a spatio-temporal graph neural network for flood prediction
- Part of
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 08 November 2024, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reconfigurable cable-driven parallel mechanism design: physical constraints and control
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Expansion of the critical intensity for the random connection model
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 08 November 2024, pp. 158-209
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Investigating the influence and interplay of physical and virtual traits on the user perception of Mixed Reality prototypes
-
- Journal:
- Design Science / Volume 10 / 2024
- Published online by Cambridge University Press:
- 08 November 2024, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Probabilistic Answer Set Programming with Discrete and Continuous Random Variables
-
- Journal:
- Theory and Practice of Logic Programming / Volume 25 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 08 November 2024, pp. 1-32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Machine Learning Evaluation
- Towards Reliable and Responsible AI
-
- Published online:
- 07 November 2024
- Print publication:
- 21 November 2024
Multi-model workload specifications and their application to cyber-physical systems – ERRATUM
-
- Journal:
- Research Directions: Cyber-Physical Systems / Volume 2 / 2024
- Published online by Cambridge University Press:
- 07 November 2024, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The need for climate data stewardship: 10 tensions and reflections regarding climate data governance
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 07 November 2024, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Augmentation or replication? Assessing big data’s role in migration studies
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 07 November 2024, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What can we learn about mental health from 10,933 patient lived experiences using a novel quantitative-qualitative network analysis?
-
- Journal:
- Network Science / Volume 12 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 07 November 2024, pp. 321-338
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
