Refine search
Actions for selected content:
49522 results in Computer Science
17 - Estimating the Standard Error: Analytic Approximations, the Jackknife, and the Bootstrap
-
- Book:
- Introduction to Probability and Statistics for Data Science
- Published online:
- 13 December 2024
- Print publication:
- 14 November 2024, pp 645-683
-
- Chapter
- Export citation
12 - Hypothesis Tests for Two or More Populations
-
- Book:
- Introduction to Probability and Statistics for Data Science
- Published online:
- 13 December 2024
- Print publication:
- 14 November 2024, pp 386-458
-
- Chapter
- Export citation
10 - Confidence Intervals
-
- Book:
- Introduction to Probability and Statistics for Data Science
- Published online:
- 13 December 2024
- Print publication:
- 14 November 2024, pp 302-347
-
- Chapter
- Export citation
18 - Generalized Linear Models and Regression Trees
-
- Book:
- Introduction to Probability and Statistics for Data Science
- Published online:
- 13 December 2024
- Print publication:
- 14 November 2024, pp 684-750
-
- Chapter
- Export citation
-
Summary
In Chapter 14 we studied multiple regression and polynomial regression and how these techniques can be used to determine the relationship between an outcome
and several predictor variables
5 - Discrete Distributions
-
- Book:
- Introduction to Probability and Statistics for Data Science
- Published online:
- 13 December 2024
- Print publication:
- 14 November 2024, pp 132-169
-
- Chapter
- Export citation
Analytical derivation of singularity-free tubes in the constant-orientation workspace of 6-6 Stewart platform manipulators
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper presents the novel concept of a singularity-free tube (SFT) in the constant orientation workspace of a spatial parallel manipulator. The concept is developed and demonstrated in the context of a
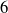 $6$-
$6$-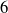 $6$ spatial parallel manipulator, namely, the semi-regular Stewart platform manipulator. Given two points in the said workspace, the SFT is a tubular volume which contains these points and is free of gain-type or forward-kinematic singularities. The purpose of identifying such regions in space is to allow abundant freedom to the path-planner to connect the said points by a path, which can be free of gain-type singularities simply by remaining inside the SFT at all times. To demonstrate the concept, two smooth paths obtained by formulating two different optimisation problems have been presented as examples. The SFT can be of great help in singularity-free path-planning in many similar manipulators.
$6$ spatial parallel manipulator, namely, the semi-regular Stewart platform manipulator. Given two points in the said workspace, the SFT is a tubular volume which contains these points and is free of gain-type or forward-kinematic singularities. The purpose of identifying such regions in space is to allow abundant freedom to the path-planner to connect the said points by a path, which can be free of gain-type singularities simply by remaining inside the SFT at all times. To demonstrate the concept, two smooth paths obtained by formulating two different optimisation problems have been presented as examples. The SFT can be of great help in singularity-free path-planning in many similar manipulators.
Robust pollination for tomato farming using deep learning and visual servoing
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Generating Global and Local Explanations for Tree-Ensemble Learning Methods by Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 13 November 2024, pp. 973-1010
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ROB volume 42 issue 8 Cover and Front matter
-
- Article
-
- You have access
- Export citation
ROB volume 42 issue 8 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Developing and evaluating a design method for positive artificial intelligence
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Flexible multi-fidelity framework for load estimation of wind farms through graph neural networks and transfer learning
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 12 November 2024, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analyzing problem framing in design teams: a systems mapping approach
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dynamic semantic networks for exploration of creative thinking
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Discussing the spectrum of physics-enhanced machine learning: a survey on structural mechanics applications
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 12 November 2024, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cloudy with a chance of precision: satellite’s autoconversion rates forecasting powered by machine learning
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 11 November 2024, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
