Refine search
Actions for selected content:
49496 results in Computer Science
Robust pollination for tomato farming using deep learning and visual servoing
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Generating Global and Local Explanations for Tree-Ensemble Learning Methods by Answer Set Programming
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 5 / September 2024
- Published online by Cambridge University Press:
- 13 November 2024, pp. 973-1010
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ROB volume 42 issue 8 Cover and Front matter
-
- Article
-
- You have access
- Export citation
ROB volume 42 issue 8 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Developing and evaluating a design method for positive artificial intelligence
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Flexible multi-fidelity framework for load estimation of wind farms through graph neural networks and transfer learning
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 12 November 2024, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analyzing problem framing in design teams: a systems mapping approach
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dynamic semantic networks for exploration of creative thinking
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Discussing the spectrum of physics-enhanced machine learning: a survey on structural mechanics applications
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 12 November 2024, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cloudy with a chance of precision: satellite’s autoconversion rates forecasting powered by machine learning
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 11 November 2024, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Almost exact recovery in noisy semi-supervised learning
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 39 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 11 November 2024, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reinforcement actor-critic learning as a rehearsal in MicroRTS
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 39 / 2024
- Published online by Cambridge University Press:
- 08 November 2024, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Unmasking the role of remote sensors in comfort, energy, and demand response
- Part of
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 08 November 2024, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Groupoidal realizability for intensional type theory
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 9 / October 2024
- Published online by Cambridge University Press:
- 08 November 2024, pp. 911-944
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data-driven decarbonization framework with machine learning
- Part of
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 08 November 2024, e22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Optimal approximate minimization of one-letter weighted finite automata
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 8 / September 2024
- Published online by Cambridge University Press:
- 08 November 2024, pp. 807-833
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we study the approximate minimization problem of weighted finite automata (WFAs): to compute the best possible approximation of a WFA given a bound on the number of states. By reformulating the problem in terms of Hankel matrices, we leverage classical results on the approximation of Hankel operators, namely the celebrated Adamyan-Arov-Krein (AAK) theory. We solve the optimal spectral-norm approximate minimization problem for irredundant WFAs with real weights, defined over a one-letter alphabet. We present a theoretical analysis based on AAK theory and bounds on the quality of the approximation in the spectral norm and
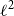 $\ell ^2$ norm. Moreover, we provide a closed-form solution, and an algorithm, to compute the optimal approximation of a given size in polynomial time.
$\ell ^2$ norm. Moreover, we provide a closed-form solution, and an algorithm, to compute the optimal approximation of a given size in polynomial time.