Refine search
Actions for selected content:
49525 results in Computer Science
The need for climate data stewardship: 10 tensions and reflections regarding climate data governance
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 07 November 2024, e52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Augmentation or replication? Assessing big data’s role in migration studies
- Part of
-
- Journal:
- Data & Policy / Volume 6 / 2024
- Published online by Cambridge University Press:
- 07 November 2024, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
What can we learn about mental health from 10,933 patient lived experiences using a novel quantitative-qualitative network analysis?
-
- Journal:
- Network Science / Volume 12 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 07 November 2024, pp. 321-338
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multilayer network games: A cooperative approach
-
- Journal:
- Network Science / Volume 12 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 07 November 2024, pp. 392-403
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Has bitcoin been dethroned too quickly? The cryptocurrency return networks
-
- Journal:
- Network Science / Volume 13 / 2025
- Published online by Cambridge University Press:
- 07 November 2024, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
End-to-end deep learning-based framework for path planning and collision checking: bin-picking application – ERRATUM
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Top-k high utility itemset mining: current status and future directions
-
- Journal:
- The Knowledge Engineering Review / Volume 39 / 2024
- Published online by Cambridge University Press:
- 06 November 2024, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
High utility itemsets mining (HUIM) is an important sub-field of frequent itemset mining (FIM). Recently, HUIM has received much attention in the field of data mining. High utility itemsets (HUIs) have proven to be quite useful in marketing, retail marketing, cross-marketing, and e-commerce. Traditional HUIM approaches suffer from a drawback as they need a user-defined minimum utility (
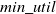 $ min\_util $) threshold. It is not easy for the users to set the appropriate
$ min\_util $) threshold. It is not easy for the users to set the appropriate 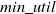 $ min\_util $ threshold to find actionable HUIs. To target this drawback, top-k HUIM has been introduced. top-k HUIM is more suitable for supermarket managers and retailers to prepare appropriate strategies to generate higher profit. In this paper, we provide an in-depth survey of the current status of top-k HUIM approaches. The paper presents the task of top-k HUIM and its relevant definitions. It reviews the top-k HUIM approaches and presents their advantages and disadvantages. The paper also discusses the important strategies of the top-k HUIM, their variations, and research opportunities. The paper provides a detailed summary, analysis, and future directions of the top-k HUIM field.
$ min\_util $ threshold to find actionable HUIs. To target this drawback, top-k HUIM has been introduced. top-k HUIM is more suitable for supermarket managers and retailers to prepare appropriate strategies to generate higher profit. In this paper, we provide an in-depth survey of the current status of top-k HUIM approaches. The paper presents the task of top-k HUIM and its relevant definitions. It reviews the top-k HUIM approaches and presents their advantages and disadvantages. The paper also discusses the important strategies of the top-k HUIM, their variations, and research opportunities. The paper provides a detailed summary, analysis, and future directions of the top-k HUIM field.
Template-based piecewise affine regression
-
- Journal:
- Research Directions: Cyber-Physical Systems / Volume 2 / 2024
- Published online by Cambridge University Press:
- 06 November 2024, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A data density-based measure of dexterity for continuum robots and its comparative study
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Wb-sober spaces and the core-coherence of dcpo models
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 6 / June 2024
- Published online by Cambridge University Press:
- 06 November 2024, pp. 529-550
-
- Article
- Export citation
-
In this paper, we introduce a new class of
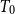 $T_0$ spaces called wb-sober spaces, which is strictly larger than the class of open well-filtered spaces. Unlike open well-filtered spaces, wb-sober spaces are defined more intuitively by requiring certain special subsets, termed wb-irreducible closed sets, to have singleton closures. We establish several key results about these spaces, including (1) every open well-filtered space is wb-sober, but not vice versa; (2) every strongly core-coherent wb-sober space is open well-filtered; (3) a space is core-compact iff its irreducible closed sets are wb-irreducible, providing a characterization of core-compactness; (4) every core-compact wb-sober space is sober, thereby generalizing the Jia-Jung problem. In addition, we investigate the core-coherence of the Xi-Zhao model. We prove that a
$T_0$ spaces called wb-sober spaces, which is strictly larger than the class of open well-filtered spaces. Unlike open well-filtered spaces, wb-sober spaces are defined more intuitively by requiring certain special subsets, termed wb-irreducible closed sets, to have singleton closures. We establish several key results about these spaces, including (1) every open well-filtered space is wb-sober, but not vice versa; (2) every strongly core-coherent wb-sober space is open well-filtered; (3) a space is core-compact iff its irreducible closed sets are wb-irreducible, providing a characterization of core-compactness; (4) every core-compact wb-sober space is sober, thereby generalizing the Jia-Jung problem. In addition, we investigate the core-coherence of the Xi-Zhao model. We prove that a 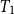 $T_1$ space contains finite number of isolated points iff its Xi-Zhao model is core-coherent iff its Xi-Zhao model is strongly core-coherent. Based on this result, we then propose a general approach to constructing a non-routine open well-filtered but not well-filtered dcpo.
$T_1$ space contains finite number of isolated points iff its Xi-Zhao model is core-coherent iff its Xi-Zhao model is strongly core-coherent. Based on this result, we then propose a general approach to constructing a non-routine open well-filtered but not well-filtered dcpo.
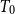
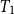
Development of a seat support mechanism for guiding users to an appropriate posture in a seated-style echocardiography robot
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On the Equivalence between Logic Programming and SETAF
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 6 / November 2024
- Published online by Cambridge University Press:
- 06 November 2024, pp. 1208-1236
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
A framework with sets of attacking arguments (
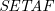 $\textit{SETAF}$) is an extension of the well-known Dung’s Abstract Argumentation Frameworks (
$\textit{SETAF}$) is an extension of the well-known Dung’s Abstract Argumentation Frameworks (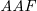 $\mathit{AAF}$s) that allows joint attacks on arguments. In this paper, we provide a translation from Normal Logic Programs (
$\mathit{AAF}$s) that allows joint attacks on arguments. In this paper, we provide a translation from Normal Logic Programs (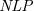 $\textit{NLP}$s) to
$\textit{NLP}$s) to 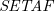 $\textit{SETAF}$s and vice versa, from
$\textit{SETAF}$s and vice versa, from 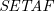 $\textit{SETAF}$s to
$\textit{SETAF}$s to 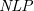 $\textit{NLP}$s. We show that there is pairwise equivalence between their semantics, including the equivalence between
$\textit{NLP}$s. We show that there is pairwise equivalence between their semantics, including the equivalence between 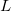 $L$-stable and semi-stable semantics. Furthermore, for a class of
$L$-stable and semi-stable semantics. Furthermore, for a class of 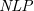 $\textit{NLP}$s called Redundancy-Free Atomic Logic Programs (
$\textit{NLP}$s called Redundancy-Free Atomic Logic Programs (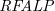 $\textit{RFALP}$s), there is also a structural equivalence as these back-and-forth translations are each other’s inverse. Then, we show that
$\textit{RFALP}$s), there is also a structural equivalence as these back-and-forth translations are each other’s inverse. Then, we show that 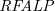 $\textit{RFALP}$s are as expressive as
$\textit{RFALP}$s are as expressive as 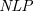 $\textit{NLP}$s by transforming any
$\textit{NLP}$s by transforming any 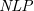 $\textit{NLP}$ into an equivalent
$\textit{NLP}$ into an equivalent 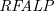 $\textit{RFALP}$ through a series of program transformations already known in the literature. We also show that these program transformations are confluent, meaning that every
$\textit{RFALP}$ through a series of program transformations already known in the literature. We also show that these program transformations are confluent, meaning that every 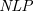 $\textit{NLP}$ will be transformed into a unique
$\textit{NLP}$ will be transformed into a unique 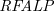 $\textit{RFALP}$. The results presented in this paper enhance our understanding that
$\textit{RFALP}$. The results presented in this paper enhance our understanding that 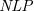 $\textit{NLP}$s and
$\textit{NLP}$s and 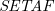 $\textit{SETAF}$s are essentially the same formalism.
$\textit{SETAF}$s are essentially the same formalism.
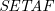
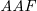
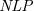
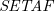
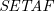
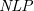
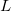
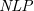
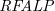
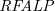
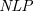
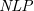
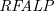
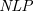
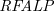
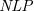
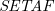
Smooth and proper maps with respect to a fibration
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 9 / October 2024
- Published online by Cambridge University Press:
- 06 November 2024, pp. 971-984
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This paper explain how the geometric notions of local contractibility and properness are related to the
 $\Sigma$-types and
$\Sigma$-types and  $\Pi$-types constructors of dependent type theory. We shall see how every Grothendieck fibration comes canonically with such a pair of notions—called smooth and proper maps—and how this recovers the previous examples and many more. This paper uses category theory to reveal a common structure between geometry and logic, with the hope that the parallel will be beneficial to both fields. The style is mostly expository, and the main results are proved in external references.
$\Pi$-types constructors of dependent type theory. We shall see how every Grothendieck fibration comes canonically with such a pair of notions—called smooth and proper maps—and how this recovers the previous examples and many more. This paper uses category theory to reveal a common structure between geometry and logic, with the hope that the parallel will be beneficial to both fields. The style is mostly expository, and the main results are proved in external references.
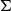
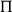
Gauging the effectiveness of a mobile application for learning English phrasal verbs
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The effect of textual and textual-pictorial glosses on incidental vocabulary learning in mobile-assisted listening
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Design of a wire-driven parallel robot for wind tunnel test based on the analysis of stiffness and workspace
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data fusion of sparse, heterogeneous, and mobile sensor devices using adaptive distance attention
-
- Journal:
- Environmental Data Science / Volume 3 / 2024
- Published online by Cambridge University Press:
- 05 November 2024, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In environmental science, where information from sensor devices are sparse, data fusion for mapping purposes is often based on geostatistical approaches. We propose a methodology called adaptive distance attention that enables us to fuse sparse, heterogeneous, and mobile sensor devices and predict values at locations with no previous measurement. The approach allows for automatically weighting the measurements according to a priori quality information about the sensor device without using complex and resource-demanding data assimilation techniques. Both ordinary kriging and the general regression neural network (GRNN) are integrated into this attention with their learnable parameters based on deep learning architectures. We evaluate this method using three static phenomena with different complexities: a case related to a simplistic phenomenon, topography over an area of 196
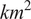 $ {km}^2 $ and to the annual hourly
$ {km}^2 $ and to the annual hourly 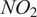 $ {NO}_2 $ concentration in 2019 over the Oslo metropolitan region (1026
$ {NO}_2 $ concentration in 2019 over the Oslo metropolitan region (1026 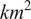 $ {km}^2 $). We simulate networks of 100 synthetic sensor devices with six characteristics related to measurement quality and measurement spatial resolution. Generally, outcomes are promising: we significantly improve the metrics from baseline geostatistical models. Besides, distance attention using the Nadaraya–Watson kernel provides as good metrics as the attention based on the kriging system enabling the possibility to alleviate the processing cost for fusion of sparse data. The encouraging results motivate us in keeping adapting distance attention to space-time phenomena evolving in complex and isolated areas.
$ {km}^2 $). We simulate networks of 100 synthetic sensor devices with six characteristics related to measurement quality and measurement spatial resolution. Generally, outcomes are promising: we significantly improve the metrics from baseline geostatistical models. Besides, distance attention using the Nadaraya–Watson kernel provides as good metrics as the attention based on the kriging system enabling the possibility to alleviate the processing cost for fusion of sparse data. The encouraging results motivate us in keeping adapting distance attention to space-time phenomena evolving in complex and isolated areas.
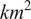
Monitoring-supported value generation for managing structures and infrastructure systems
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 04 November 2024, e27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Symmetric monoidal smash products in homotopy type theory
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 9 / October 2024
- Published online by Cambridge University Press:
- 04 November 2024, pp. 985-1007
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
