Refine search
Actions for selected content:
48284 results in Computer Science
1 - Matrix Theory
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 February 2023
- Print publication:
- 22 December 2022, pp 1-58
-
- Chapter
- Export citation
20 - Convergence Analysis II: Stochastic Subgradient Algorithms
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 February 2023
- Print publication:
- 22 December 2022, pp 730-755
-
- Chapter
- Export citation
52 - Nearest-Neighbor Rule
-
- Book:
- Inference and Learning from Data
- Published online:
- 24 February 2023
- Print publication:
- 22 December 2022, pp 2260-2289
-
- Chapter
- Export citation
-
Summary
We encountered one instance of Bayesian inference in Chapter 50, based on the quadratic loss in the context of mean-square-error (MSE) estimation. We explained there that the optimal solution for inferring a hidden zero-mean random variable
from observations of another zero-mean random variable
72 - Meta Learning
-
- Book:
- Inference and Learning from Data
- Published online:
- 24 February 2023
- Print publication:
- 22 December 2022, pp 3099-3148
-
- Chapter
- Export citation
65 - Feedforward Neural Networks
-
- Book:
- Inference and Learning from Data
- Published online:
- 24 February 2023
- Print publication:
- 22 December 2022, pp 2715-2796
-
- Chapter
- Export citation
63 - Kernel Methods
-
- Book:
- Inference and Learning from Data
- Published online:
- 24 February 2023
- Print publication:
- 22 December 2022, pp 2587-2649
-
- Chapter
- Export citation
49 - Policy Gradient Methods
-
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 March 2023
- Print publication:
- 22 December 2022, pp 2047-2120
-
- Chapter
- Export citation
-
Summary
In most multistage decision problems, we are interested in determining the optimal strategy,
17 - Adaptive Gradient Methods
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 February 2023
- Print publication:
- 22 December 2022, pp 599-641
-
- Chapter
- Export citation
46 - Temporal Difference Learning
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 March 2023
- Print publication:
- 22 December 2022, pp 1917-1970
-
- Chapter
- Export citation
58 - Dictionary Learning
-
- Book:
- Inference and Learning from Data
- Published online:
- 24 February 2023
- Print publication:
- 22 December 2022, pp 2424-2456
-
- Chapter
- Export citation
-
Summary
Principal component analysis (PCA) is a formidable tool for dimensionality reduction. Given feature vectors
8 - Gaussian Distribution
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 February 2023
- Print publication:
- 22 December 2022, pp 261-301
-
- Chapter
- Export citation
Preface
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 March 2023
- Print publication:
- 22 December 2022, pp xxvii-xliv
-
- Chapter
- Export citation
44 - Markov Decision Processes
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 March 2023
- Print publication:
- 22 December 2022, pp 1807-1852
-
- Chapter
- Export citation
Subject Index
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 March 2023
- Print publication:
- 22 December 2022, pp 2145-2164
-
- Chapter
- Export citation
69 - Recurrent Networks
-
- Book:
- Inference and Learning from Data
- Published online:
- 24 February 2023
- Print publication:
- 22 December 2022, pp 2967-3041
-
- Chapter
- Export citation
14 - Subgradient Method
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 February 2023
- Print publication:
- 22 December 2022, pp 471-506
-
- Chapter
- Export citation
24 - Nonconvex Optimization
-
- Book:
- Inference and Learning from Data
- Published online:
- 17 February 2023
- Print publication:
- 22 December 2022, pp 852-901
-
- Chapter
- Export citation
68 - Generative Networks
-
- Book:
- Inference and Learning from Data
- Published online:
- 24 February 2023
- Print publication:
- 22 December 2022, pp 2905-2966
-
- Chapter
- Export citation
Toward random walk-based clustering of variable-order networks
-
- Journal:
- Network Science / Volume 10 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 22 December 2022, pp. 381-399
-
- Article
- Export citation
-
Higher-order networks aim at improving the classical network representation of trajectories data as memory-less order
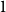 $1$ Markov models. To do so, locations are associated with different representations or “memory nodes” representing indirect dependencies between visited places as direct relations. One promising area of investigation in this context is variable-order network models as it was suggested by Xu et al. that random walk-based mining tools can be directly applied on such networks. In this paper, we focus on clustering algorithms and show that doing so leads to biases due to the number of nodes representing each location. To address them, we introduce a representation aggregation algorithm that produces smaller yet still accurate network models of the input sequences. We empirically compare the clustering found with multiple network representations of real-world mobility datasets. As our model is limited to a maximum order of
$1$ Markov models. To do so, locations are associated with different representations or “memory nodes” representing indirect dependencies between visited places as direct relations. One promising area of investigation in this context is variable-order network models as it was suggested by Xu et al. that random walk-based mining tools can be directly applied on such networks. In this paper, we focus on clustering algorithms and show that doing so leads to biases due to the number of nodes representing each location. To address them, we introduce a representation aggregation algorithm that produces smaller yet still accurate network models of the input sequences. We empirically compare the clustering found with multiple network representations of real-world mobility datasets. As our model is limited to a maximum order of 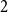 $2$, we discuss further generalizations of our method to higher orders.
$2$, we discuss further generalizations of our method to higher orders.
50 - Least-Squares Problems
-
- Book:
- Inference and Learning from Data
- Published online:
- 24 February 2023
- Print publication:
- 22 December 2022, pp 2165-2220
-
- Chapter
- Export citation
-
Summary
We studied in Chapters 29 and 30 the mean‐square error (MSE) criterion in some detail, and applied it to the problem of inferring an unknown (or hidden) variable
