Refine search
Actions for selected content:
48276 results in Computer Science
Variable ranking and selection with random forest for unbalanced data
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 20 December 2022, e30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Week-ahead solar irradiance forecasting with deep sequence learning
- Part of
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 20 December 2022, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
An introduction to radical participatory design: decolonising participatory design processes
-
- Journal:
- Design Science / Volume 8 / 2022
- Published online by Cambridge University Press:
- 20 December 2022, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A climatic random forest model of agricultural insurance loss for the Northwest United States
- Part of
-
- Journal:
- Environmental Data Science / Volume 1 / 2022
- Published online by Cambridge University Press:
- 20 December 2022, e29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We compared climatic relationships to insurance loss across the inland Pacific Northwest region of the United States, using a design matrix methodology, to identify optimum temporal windows for climate variables by county in relationship to wheat insurance loss due to drought. The results of our temporal window construction for water availability variables (precipitation, temperature, evapotranspiration, and the Palmer drought severity index [PDSI]) identified spatial patterns across the study area that aligned with regional climate patterns, particularly with regards to drought-prone counties of eastern Washington. Using these optimum time-lagged correlational relationships between insurance loss and individual climate variables, along with commodity pricing, we constructed a regression-based random forest model for insurance loss prediction and evaluation of climatic feature importance. Our cross-validated model results indicated that PDSI was the most important factor in predicting total seasonal wheat/drought insurance loss, with wheat pricing and potential evapotranspiration having noted contributions. Our overall regional model had a
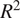 $ {R}^2 $ of 0.49, and a RMSE of $30.8 million. Model performance typically underestimated annual losses, with moderate spatial variability in terms of performance between counties.
$ {R}^2 $ of 0.49, and a RMSE of $30.8 million. Model performance typically underestimated annual losses, with moderate spatial variability in terms of performance between counties.
Parameter-efficient feature-based transfer for paraphrase identification
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 19 December 2022, pp. 1066-1096
-
- Article
- Export citation
Emerging trends: Unfair, biased, addictive, dangerous, deadly, and insanely profitable
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 19 December 2022, pp. 483-508
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Rethinking technologies of remembering for a postcolonial world
- Part of
-
- Journal:
- Memory, Mind & Media / Volume 1 / 2022
- Published online by Cambridge University Press:
- 19 December 2022, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Connecting Discrete Mathematics and Computer Science
-
- Published online:
- 16 December 2022
- Print publication:
- 04 August 2022
-
- Textbook
- Export citation
A special issue on categorical algebras and computation in celebration of John Power’s 60th birthday, part II
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 4 / April 2022
- Published online by Cambridge University Press:
- 16 December 2022, p. 348
-
- Article
-
- You have access
- HTML
- Export citation
References
-
- Book:
- Exponential Families in Theory and Practice
- Published online:
- 25 November 2022
- Print publication:
- 15 December 2022, pp 239-242
-
- Chapter
- Export citation
3 - Generalized Linear Models
-
- Book:
- Exponential Families in Theory and Practice
- Published online:
- 25 November 2022
- Print publication:
- 15 December 2022, pp 88-140
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Exponential Families in Theory and Practice
- Published online:
- 25 November 2022
- Print publication:
- 15 December 2022, pp i-iv
-
- Chapter
- Export citation
Introduction
-
- Book:
- Exponential Families in Theory and Practice
- Published online:
- 25 November 2022
- Print publication:
- 15 December 2022, pp xi-xii
-
- Chapter
- Export citation
Diversity, networks, and innovation: A text analytic approach to measuring expertise diversity
-
- Journal:
- Network Science / Volume 11 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 15 December 2022, pp. 36-64
-
- Article
- Export citation
Preface
-
- Book:
- Exponential Families in Theory and Practice
- Published online:
- 25 November 2022
- Print publication:
- 15 December 2022, pp vii-viii
-
- Chapter
- Export citation
4 - Curved Exponential Families, Empirical Bayes, Missing Data, and Stability of the MLE
-
- Book:
- Exponential Families in Theory and Practice
- Published online:
- 25 November 2022
- Print publication:
- 15 December 2022, pp 141-182
-
- Chapter
- Export citation
5 - Bootstrap Confidence Intervals
-
- Book:
- Exponential Families in Theory and Practice
- Published online:
- 25 November 2022
- Print publication:
- 15 December 2022, pp 183-238
-
- Chapter
- Export citation
Acknowledgments
-
- Book:
- Exponential Families in Theory and Practice
- Published online:
- 25 November 2022
- Print publication:
- 15 December 2022, pp ix-x
-
- Chapter
- Export citation
Multimodal mechanisms of political discourse dynamics and the case of Germany’s nuclear energy phase-out
-
- Journal:
- Network Science / Volume 11 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 15 December 2022, pp. 205-223
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
