Refine search
Actions for selected content:
48453 results in Computer Science

Algorithm Design with Haskell
-
- Published online:
- 25 June 2020
- Print publication:
- 09 July 2020
Index
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 154-156
-
- Chapter
- Export citation
2 - Should Artificial Intelligence Pay Taxes?
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 36-49
-
- Chapter
- Export citation
Bibliography
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 246-269
-
- Chapter
- Export citation
Dedication
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp v-vi
-
- Chapter
- Export citation
Introduction: Artificial Intelligence and the Law
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 1-17
-
- Chapter
- Export citation
Contents
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp vii-x
-
- Chapter
- Export citation
1 - Understanding Artificial Intelligence
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 18-35
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp i-iv
-
- Chapter
- Export citation
3 - Reasonable Robots
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 50-70
-
- Chapter
- Export citation
5 - Everything Is Obvious
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 92-110
-
- Chapter
- Export citation
Dedication
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp v-vi
-
- Chapter
- Export citation
Part One - Fundamentals
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 1-2
-
- Chapter
- Export citation
Index
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 270-274
-
- Chapter
- Export citation
WITTGENSTEIN’S ELIMINATION OF IDENTITY FOR QUANTIFIER-FREE LOGIC
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 June 2020, pp. 1-21
- Print publication:
- March 2021
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
One of the central logical ideas in Wittgenstein’s Tractatus logico-philosophicus is the elimination of the identity sign in favor of the so-called “exclusive interpretation” of names and quantifiers requiring different names to refer to different objects and (roughly) different variables to take different values. In this paper, we examine a recent development of these ideas in papers by Kai Wehmeier. We diagnose two main problems of Wehmeier’s account, the first concerning the treatment of individual constants, the second concerning so-called “pseudo-propositions” (Scheinsätze) of classical logic such as
 $a=a$ or
$a=a$ or 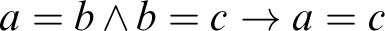 $a=b \wedge b=c \rightarrow a=c$. We argue that overcoming these problems requires two fairly drastic departures from Wehmeier’s account: (1) Not every formula of classical first-order logic will be translatable into a single formula of Wittgenstein’s exclusive notation. Instead, there will often be a multiplicity of possible translations, revealing the original “inclusive” formulas to be ambiguous. (2) Certain formulas of first-order logic such as
$a=b \wedge b=c \rightarrow a=c$. We argue that overcoming these problems requires two fairly drastic departures from Wehmeier’s account: (1) Not every formula of classical first-order logic will be translatable into a single formula of Wittgenstein’s exclusive notation. Instead, there will often be a multiplicity of possible translations, revealing the original “inclusive” formulas to be ambiguous. (2) Certain formulas of first-order logic such as  $a=a$ will not be translatable into Wittgenstein’s notation at all, being thereby revealed as nonsensical pseudo-propositions which should be excluded from a “correct” conceptual notation. We provide translation procedures from inclusive quantifier-free logic into the exclusive notation that take these modifications into account and define a notion of logical equivalence suitable for assessing these translations.
$a=a$ will not be translatable into Wittgenstein’s notation at all, being thereby revealed as nonsensical pseudo-propositions which should be excluded from a “correct” conceptual notation. We provide translation procedures from inclusive quantifier-free logic into the exclusive notation that take these modifications into account and define a notion of logical equivalence suitable for assessing these translations.


6 - Graph Data
- from Part II - Case Studies
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 139-162
-
- Chapter
- Export citation
Copyright page
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp iv-iv
-
- Chapter
- Export citation
5 - Advanced Topics: Variable-Length Data and Automated Feature Engineering
- from Part One - Fundamentals
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 112-136
-
- Chapter
- Export citation
7 - Alternative Perspectives on AI Legal Neutrality
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 134-143
-
- Chapter
- Export citation
