Refine search
Actions for selected content:
48462 results in Computer Science
Predicting human design decisions with deep recurrent neural network combining static and dynamic data
- Part of
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 03 July 2020, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A framework for studying design thinking through measuring designers’ minds, bodies and brains
- Part of
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 03 July 2020, e19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Empathic accuracy in design: Exploring design outcomes through empathic performance and physiology
- Part of
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 03 July 2020, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
KNOWLEDGE, JUSTIFICATION, AND ADEQUATE REASONS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 02 July 2020, pp. 687-727
- Print publication:
- September 2021
-
- Article
- Export citation
A NOTE ON THE SEQUENT CALCULI
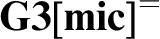 ${{{\bf G3}[{\bf mic}]}}^{=}$
${{{\bf G3}[{\bf mic}]}}^{=}$
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 02 July 2020, pp. 537-551
- Print publication:
- June 2022
-
- Article
- Export citation
-
We show that the replacement rule of the sequent calculi
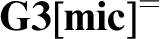 ${\bf G3[mic]}^= $ in [8] can be replaced by the simpler rule in which one of the principal formulae is not repeated in the premiss.
${\bf G3[mic]}^= $ in [8] can be replaced by the simpler rule in which one of the principal formulae is not repeated in the premiss.
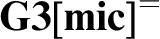
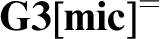
Linguistic knowledge-based vocabularies for Neural Machine Translation
-
- Journal:
- Natural Language Engineering / Volume 27 / Issue 4 / July 2021
- Published online by Cambridge University Press:
- 02 July 2020, pp. 485-506
-
- Article
- Export citation
Crowd-assessing quality in uncertain data linking datasets
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 35 / 2020
- Published online by Cambridge University Press:
- 02 July 2020, e33
-
- Article
- Export citation
A BRIDGE BETWEEN Q-WORLDS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 02 July 2020, pp. 447-486
- Print publication:
- June 2021
-
- Article
- Export citation
DEPENDENT CHOICE, PROPERNESS, AND GENERIC ABSOLUTENESS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 02 July 2020, pp. 225-249
- Print publication:
- March 2021
-
- Article
- Export citation
-
We show that Dependent Choice is a sufficient choice principle for developing the basic theory of proper forcing, and for deriving generic absoluteness for the Chang model in the presence of large cardinals, even with respect to
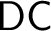 $\mathsf {DC}$-preserving symmetric submodels of forcing extensions. Hence,
$\mathsf {DC}$-preserving symmetric submodels of forcing extensions. Hence,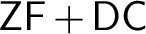 $\mathsf {ZF}+\mathsf {DC}$ not only provides the right framework for developing classical analysis, but is also the right base theory over which to safeguard truth in analysis from the independence phenomenon in the presence of large cardinals. We also investigate some basic consequences of the Proper Forcing Axiom in
$\mathsf {ZF}+\mathsf {DC}$ not only provides the right framework for developing classical analysis, but is also the right base theory over which to safeguard truth in analysis from the independence phenomenon in the presence of large cardinals. We also investigate some basic consequences of the Proper Forcing Axiom in $\mathsf {ZF}$, and formulate a natural question about the generic absoluteness of the Proper Forcing Axiom in
$\mathsf {ZF}$, and formulate a natural question about the generic absoluteness of the Proper Forcing Axiom in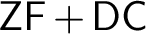 $\mathsf {ZF}+\mathsf {DC}$ and
$\mathsf {ZF}+\mathsf {DC}$ and $\mathsf {ZFC}$. Our results confirm
$\mathsf {ZFC}$. Our results confirm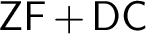 $\mathsf {ZF} + \mathsf {DC}$ as a natural foundation for a significant portion of “classical mathematics” and provide support to the idea of this theory being also a natural foundation for a large part of set theory.
$\mathsf {ZF} + \mathsf {DC}$ as a natural foundation for a significant portion of “classical mathematics” and provide support to the idea of this theory being also a natural foundation for a large part of set theory.


The National Cancer Institute Cancer Moonshot Public Access and Data Sharing Policy—Initial assessment and implications
-
- Journal:
- Data & Policy / Volume 2 / 2020
- Published online by Cambridge University Press:
- 02 July 2020, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Introduction to the Special Issue on Logic Rules and Reasoning: Selected Papers from the 2nd International Joint Conference on Rules and Reasoning (RuleML+RR 2018)
-
- Journal:
- Theory and Practice of Logic Programming / Volume 21 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 30 June 2020, pp. 1-3
-
- Article
-
- You have access
- Export citation
Constructing families of cospectral regular graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 30 June 2020, pp. 664-671
-
- Article
- Export citation
Ramsey properties of randomly perturbed graphs: cliques and cycles
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 30 June 2020, pp. 830-867
-
- Article
- Export citation
An approximate version of Jackson’s conjecture
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 30 June 2020, pp. 886-899
-
- Article
- Export citation
On finite sets of small tripling or small alternation in arbitrary groups
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 30 June 2020, pp. 807-829
-
- Article
- Export citation
Supervised learning for the detection of negation and of its scope in French and Brazilian Portuguese biomedical corpora
-
- Journal:
- Natural Language Engineering / Volume 27 / Issue 2 / March 2021
- Published online by Cambridge University Press:
- 30 June 2020, pp. 181-201
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Sampling biased monotonic surfaces using exponential metrics
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 30 June 2020, pp. 672-697
-
- Article
- Export citation
An Implicit Plan Still Overrides an Explicit Strategy During Visuomotor Adaptation Following Repetitive Transcranial Magnetic Stimulation of the Cerebellum
-
- Journal:
- Experimental Results / Volume 1 / 2020
- Published online by Cambridge University Press:
- 30 June 2020, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Restricted Chase Termination for Existential Rules: A Hierarchical Approach and Experimentation
-
- Journal:
- Theory and Practice of Logic Programming / Volume 21 / Issue 1 / January 2021
- Published online by Cambridge University Press:
- 30 June 2020, pp. 4-50
-
- Article
- Export citation
-
The chase procedure for existential rules is an indispensable tool for several database applications, where its termination guarantees the decidability of these tasks. Most previous studies have focused on the skolem chase variant and its termination analysis. It is known that the restricted chase variant is a more powerful tool in termination analysis provided a database is given. But all-instance termination presents a challenge since the critical database and similar techniques do not work. In this paper, we develop a novel technique to characterize the activeness of all possible cycles of a certain length for the restricted chase, which leads to the formulation of a framework of parameterized classes of the finite restricted chase, called
 $k$-$\mathsf{safe}(\Phi)$ rule sets. This approach applies to any class of finite skolem chase identified with a condition of acyclicity. More generally, we show that the approach can be applied to the hierarchy of bounded rule sets previously only defined for the skolem chase. Experiments on a collection of ontologies from the web show the applicability of the proposed methods on real-world ontologies.
$k$-$\mathsf{safe}(\Phi)$ rule sets. This approach applies to any class of finite skolem chase identified with a condition of acyclicity. More generally, we show that the approach can be applied to the hierarchy of bounded rule sets previously only defined for the skolem chase. Experiments on a collection of ontologies from the web show the applicability of the proposed methods on real-world ontologies.

