Refine search
Actions for selected content:
48453 results in Computer Science
Preface
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp xi-xii
-
- Chapter
- Export citation
8 - Textual Data
- from Part II - Case Studies
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 186-211
-
- Chapter
- Export citation
3 - Features, Expanded: Computable Features, Imputation and Kernels
- from Part One - Fundamentals
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 59-78
-
- Chapter
- Export citation
Contents
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp vii-viii
-
- Chapter
- Export citation
6 - Punishing Artificial Intelligence
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 111-133
-
- Chapter
- Export citation
Notes
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 145-153
-
- Chapter
- Export citation
2 - Features, Combined: Normalization, Discretization and Outliers
- from Part One - Fundamentals
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 34-58
-
- Chapter
- Export citation
4 - Artificial Inventors
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 71-91
-
- Chapter
- Export citation
1 - Introduction
- from Part One - Fundamentals
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 3-33
-
- Chapter
- Export citation
Third-Party Materials
-
- Book:
- The Reasonable Robot
- Published online:
- 15 June 2020
- Print publication:
- 25 June 2020, pp 144-144
-
- Chapter
- Export citation
7 - Time stamped Data
- from Part II - Case Studies
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 163-185
-
- Chapter
- Export citation
Part II - Case Studies
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 137-138
-
- Chapter
- Export citation
9 - Image Data
- from Part II - Case Studies
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 212-232
-
- Chapter
- Export citation
4 - Features, Reduced: Feature Selection, Dimensionality Reduction and Embeddings
- from Part One - Fundamentals
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 79-111
-
- Chapter
- Export citation
10 - Other Domains: Video, GIS and Preferences
- from Part II - Case Studies
-
- Book:
- The Art of Feature Engineering
- Published online:
- 29 May 2020
- Print publication:
- 25 June 2020, pp 233-245
-
- Chapter
- Export citation
Hamiltonicity in random directed graphs is born resilient
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 24 June 2020, pp. 900-942
-
- Article
- Export citation
-
Let
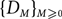 $\{D_M\}_{M\geq 0}$ be the n-vertex random directed graph process, where
$\{D_M\}_{M\geq 0}$ be the n-vertex random directed graph process, where 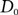 $D_0$ is the empty directed graph on n vertices, and subsequent directed graphs in the sequence are obtained by the addition of a new directed edge uniformly at random. For each
$D_0$ is the empty directed graph on n vertices, and subsequent directed graphs in the sequence are obtained by the addition of a new directed edge uniformly at random. For each 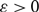 $$\varepsilon> 0$$, we show that, almost surely, any directed graph
$$\varepsilon> 0$$, we show that, almost surely, any directed graph 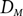 $D_M$ with minimum in- and out-degree at least 1 is not only Hamiltonian (as shown by Frieze), but remains Hamiltonian when edges are removed, as long as at most
$D_M$ with minimum in- and out-degree at least 1 is not only Hamiltonian (as shown by Frieze), but remains Hamiltonian when edges are removed, as long as at most 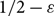 $1/2-\varepsilon$ of both the in- and out-edges incident to each vertex are removed. We say such a directed graph is
$1/2-\varepsilon$ of both the in- and out-edges incident to each vertex are removed. We say such a directed graph is 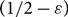 $(1/2-\varepsilon)$-resiliently Hamiltonian. Furthermore, for each
$(1/2-\varepsilon)$-resiliently Hamiltonian. Furthermore, for each 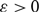 $\varepsilon > 0$, we show that, almost surely, each directed graph
$\varepsilon > 0$, we show that, almost surely, each directed graph 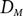 $D_M$ in the sequence is not
$D_M$ in the sequence is not 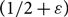 $(1/2+\varepsilon)$-resiliently Hamiltonian.
$(1/2+\varepsilon)$-resiliently Hamiltonian.This improves a result of Ferber, Nenadov, Noever, Peter and Škorić who showed, for each
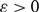 $\varepsilon > 0$, that the binomial random directed graph
$\varepsilon > 0$, that the binomial random directed graph 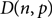 $D(n,p)$ is almost surely
$D(n,p)$ is almost surely 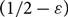 $(1/2-\varepsilon)$-resiliently Hamiltonian if
$(1/2-\varepsilon)$-resiliently Hamiltonian if 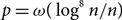 $p=\omega(\log^8n/n)$.
$p=\omega(\log^8n/n)$.
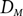
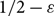
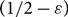
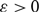
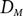
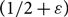
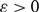
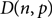
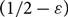
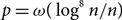
Towards the Kohayakawa–Kreuter conjecture on asymmetric Ramsey properties
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 24 June 2020, pp. 943-955
-
- Article
- Export citation
Effects of parity, sympathy and reciprocity in increasing social welfare
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 35 / 2020
- Published online by Cambridge University Press:
- 23 June 2020, e31
-
- Article
- Export citation
NASH EQUILIBRIUM STRATEGIES REVISITED IN SOFTWARE RELEASE GAMES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 36 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 23 June 2020, pp. 105-125
-
- Article
- Export citation
Supersaturation of even linear cycles in linear hypergraphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 5 / September 2020
- Published online by Cambridge University Press:
- 23 June 2020, pp. 698-721
-
- Article
- Export citation
