Refine search
Actions for selected content:
48324 results in Computer Science
2 - What Is an Algorithm?
-
- Book:
- The Age of Algorithms
- Published online:
- 17 March 2020
- Print publication:
- 16 April 2020, pp 5-18
-
- Chapter
- Export citation
20 - Time to Choose
-
- Book:
- The Age of Algorithms
- Published online:
- 17 March 2020
- Print publication:
- 16 April 2020, pp 160-160
-
- Chapter
- Export citation
Effective multi-dialectal arabic POS tagging
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 6 / November 2020
- Published online by Cambridge University Press:
- 14 April 2020, pp. 677-690
-
- Article
- Export citation
REC volume 32 issue 2 Cover and Back matter
-
- Article
-
- You have access
- Export citation
Homophily in the formation and development of learning networks among university students
-
- Journal:
- Network Science / Volume 8 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 14 April 2020, pp. 469-491
-
- Article
-
- You have access
- Open access
- Export citation
REC volume 32 issue 2 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Orchestrating DDoS mitigation via blockchain-based network provider collaborations
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 35 / 2020
- Published online by Cambridge University Press:
- 14 April 2020, e16
-
- Article
- Export citation
Exploring how design guidelines benefit design engineers: an international and global perspective
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 13 April 2020, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
AN ANALYTICAL APPROACH FOR THE BREAKDOWN DISTRIBUTION OF A THIN OXIDE
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 08 April 2020, pp. 595-610
-
- Article
- Export citation
BAYESIAN ANALYSIS OF DOUBLY STOCHASTIC MARKOV PROCESSES IN RELIABILITY
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 08 April 2020, pp. 708-729
-
- Article
- Export citation
NLE volume 26 issue 3 Cover and Front matter
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 3 / May 2020
- Published online by Cambridge University Press:
- 07 April 2020, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Heterogeneous binary random-access lists
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 30 / 2020
- Published online by Cambridge University Press:
- 07 April 2020, e10
-
- Article
-
- You have access
- Open access
- Export citation
NLE volume 26 issue 3 Cover and Back matter
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 3 / May 2020
- Published online by Cambridge University Press:
- 07 April 2020, pp. b1-b2
-
- Article
-
- You have access
- Export citation
A network tool to analyse and improve robustness of system architectures
-
- Journal:
- Design Science / Volume 6 / 2020
- Published online by Cambridge University Press:
- 07 April 2020, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Emerging trends: Subwords, seriously?
-
- Journal:
- Natural Language Engineering / Volume 26 / Issue 3 / May 2020
- Published online by Cambridge University Press:
- 07 April 2020, pp. 375-382
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Open Petri nets
-
- Journal:
- Mathematical Structures in Computer Science / Volume 30 / Issue 3 / March 2020
- Published online by Cambridge University Press:
- 07 April 2020, pp. 314-341
-
- Article
-
- You have access
- Open access
- Export citation
-
The reachability semantics for Petri nets can be studied using open Petri nets. For us, an “open” Petri net is one with certain places designated as inputs and outputs via a cospan of sets. We can compose open Petri nets by gluing the outputs of one to the inputs of another. Open Petri nets can be treated as morphisms of a category Open(Petri), which becomes symmetric monoidal under disjoint union. However, since the composite of open Petri nets is defined only up to isomorphism, it is better to treat them as morphisms of a symmetric monoidal double category
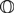 ${\mathbb O}$pen(Petri). We describe two forms of semantics for open Petri nets using symmetric monoidal double functors out of ${\mathbb O}$pen(Petri). The first, an operational semantics, gives for each open Petri net a category whose morphisms are the processes that this net can carry out. This is done in a compositional way, so that these categories can be computed on smaller subnets and then glued together. The second, a reachability semantics, simply says which markings of the outputs can be reached from a given marking of the inputs.
${\mathbb O}$pen(Petri). We describe two forms of semantics for open Petri nets using symmetric monoidal double functors out of ${\mathbb O}$pen(Petri). The first, an operational semantics, gives for each open Petri net a category whose morphisms are the processes that this net can carry out. This is done in a compositional way, so that these categories can be computed on smaller subnets and then glued together. The second, a reachability semantics, simply says which markings of the outputs can be reached from a given marking of the inputs.
Robot magic show: human–robot interaction
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 35 / 2020
- Published online by Cambridge University Press:
- 07 April 2020, e15
-
- Article
- Export citation
