Refine search
Actions for selected content:
48287 results in Computer Science
11 - An Overview of the Swedish Educational System with a Focus on Women in Computer Science
- from Part III - Cultural Perspectives from the United States and Europe
-
-
- Book:
- Cracking the Digital Ceiling
- Published online:
- 10 October 2019
- Print publication:
- 24 October 2019, pp 203-228
-
- Chapter
- Export citation
5 - Data Subject Rights and the Importance of Access
-
- Book:
- Monitoring Laws
- Published online:
- 08 November 2019
- Print publication:
- 24 October 2019, pp 78-98
-
- Chapter
- Export citation
STRONG COMPLETENESS OF MODAL LOGICS OVER 0-DIMENSIONAL METRIC SPACES
-
- Journal:
- The Review of Symbolic Logic / Volume 13 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 24 October 2019, pp. 611-632
- Print publication:
- September 2020
-
- Article
- Export citation
A relational logic for higher-order programs
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 29 / 2019
- Published online by Cambridge University Press:
- 21 October 2019, e16
-
- Article
-
- You have access
- Export citation
On the number of symbols that forces a transversal
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 21 October 2019, pp. 234-240
-
- Article
- Export citation

Next-Generation Ethics
- Engineering a Better Society
-
- Published online:
- 18 October 2019
- Print publication:
- 07 November 2019
FKN theorem for the multislice, with applications
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 18 October 2019, pp. 200-212
-
- Article
- Export citation
ORDERING RESULTS ON EXTREMES OF EXPONENTIATED LOCATION-SCALE MODELS
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 18 October 2019, pp. 331-354
-
- Article
- Export citation
NWS volume 7 issue 3 Cover and Back matter
-
- Journal:
- Network Science / Volume 7 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 18 October 2019, pp. b1-b4
-
- Article
-
- You have access
- Export citation
On Ramsey numbers of hedgehogs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 18 October 2019, pp. 101-112
-
- Article
- Export citation
-
The hedgehog Ht is a 3-uniform hypergraph on vertices
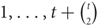 $1, \ldots ,t + \left({\matrix{t \cr 2}}\right)$ such that, for any pair (i, j) with 1 ≤ i < j ≤ t, there exists a unique vertex k > t such that {i, j, k} is an edge. Conlon, Fox and Rödl proved that the two-colour Ramsey number of the hedgehog grows polynomially in the number of its vertices, while the four-colour Ramsey number grows exponentially in the square root of the number of vertices. They asked whether the two-colour Ramsey number of the hedgehog Ht is nearly linear in the number of its vertices. We answer this question affirmatively, proving that r(Ht) = O(t2 ln t).
$1, \ldots ,t + \left({\matrix{t \cr 2}}\right)$ such that, for any pair (i, j) with 1 ≤ i < j ≤ t, there exists a unique vertex k > t such that {i, j, k} is an edge. Conlon, Fox and Rödl proved that the two-colour Ramsey number of the hedgehog grows polynomially in the number of its vertices, while the four-colour Ramsey number grows exponentially in the square root of the number of vertices. They asked whether the two-colour Ramsey number of the hedgehog Ht is nearly linear in the number of its vertices. We answer this question affirmatively, proving that r(Ht) = O(t2 ln t).
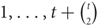
NWS volume 7 issue 3 Cover and Front matter
-
- Journal:
- Network Science / Volume 7 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 18 October 2019, pp. f1-f3
-
- Article
-
- You have access
- Export citation
WINNER PLAYS COMPETITION MODELS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 35 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 18 October 2019, pp. 236-241
-
- Article
- Export citation
On spectral embedding performance and elucidating network structure in stochastic blockmodel graphs
-
- Journal:
- Network Science / Volume 7 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 18 October 2019, pp. 269-291
-
- Article
- Export citation
Introduction
-
- Book:
- Compressed Sensing in Radar Signal Processing
- Published online:
- 30 September 2019
- Print publication:
- 17 October 2019, pp xiv-xix
-
- Chapter
- Export citation
8 - Adaptive Beamforming via Sparsity-Based Reconstruction of Covariance Matrix
-
- Book:
- Compressed Sensing in Radar Signal Processing
- Published online:
- 30 September 2019
- Print publication:
- 17 October 2019, pp 225-256
-
- Chapter
- Export citation
Index
-
- Book:
- The Digital Prism
- Published online:
- 27 September 2019
- Print publication:
- 17 October 2019, pp 170-176
-
- Chapter
- Export citation
1 - Sub-Nyquist Radar: Principles and Prototypes
-
- Book:
- Compressed Sensing in Radar Signal Processing
- Published online:
- 30 September 2019
- Print publication:
- 17 October 2019, pp 1-48
-
- Chapter
- Export citation
1 - Digital and Datafied Spaces
-
- Book:
- The Digital Prism
- Published online:
- 27 September 2019
- Print publication:
- 17 October 2019, pp 25-38
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Compressed Sensing in Radar Signal Processing
- Published online:
- 30 September 2019
- Print publication:
- 17 October 2019, pp i-iv
-
- Chapter
- Export citation
