Refine search
Actions for selected content:
48285 results in Computer Science
Expansion trees with cut
-
- Journal:
- Mathematical Structures in Computer Science / Volume 29 / Issue 8 / September 2019
- Published online by Cambridge University Press:
- 08 October 2019, pp. 1009-1029
-
- Article
- Export citation
Extensions of the Erdős–Gallai theorem and Luo’s theorem
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 08 October 2019, pp. 128-136
-
- Article
- Export citation
-
The famous Erdős–Gallai theorem on the Turán number of paths states that every graph with n vertices and m edges contains a path with at least (2m)/n edges. In this note, we first establish a simple but novel extension of the Erdős–Gallai theorem by proving that every graph G contains a path with at least
edges, where Nj(G) denotes the number of j-cliques in G for 1≤ j ≤ ω(G). We also construct a family of graphs which shows our extension improves the estimate given by the Erdős–Gallai theorem. Among applications, we show, for example, that the main results of [20], which are on the maximum possible number of s-cliques in an n-vertex graph without a path with ℓ vertices (and without cycles of length at least c), can be easily deduced from this extension. Indeed, to prove these results, Luo [20] generalized a classical theorem of Kopylov and established a tight upper bound on the number of s-cliques in an n-vertex 2-connected graph with circumference less than c. We prove a similar result for an n-vertex 2-connected graph with circumference less than c and large minimum degree. We conclude this paper with an application of our results to a problem from spectral extremal graph theory on consecutive lengths of cycles in graphs.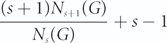 $${{(s + 1){N_{s + 1}}(G)} \over {{N_s}(G)}} + s - 1$$
$${{(s + 1){N_{s + 1}}(G)} \over {{N_s}(G)}} + s - 1$$
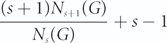
Long Monotone Trails in Random Edge-Labellings of Random Graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 29 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 08 October 2019, pp. 22-30
-
- Article
- Export citation
A special issue on structural proof theory, automated reasoning and computation in celebration of Dale Miller’s 60th birthday
-
- Journal:
- Mathematical Structures in Computer Science / Volume 29 / Issue 8 / September 2019
- Published online by Cambridge University Press:
- 08 October 2019, pp. 1007-1008
-
- Article
-
- You have access
- Export citation
ROB volume 37 issue 11 Cover and Front matter
-
- Article
-
- You have access
- Export citation
On the expressive power of user-defined effects: Effect handlers, monadic reflection, delimited control
- Part of
-
- Journal:
- Journal of Functional Programming / Volume 29 / 2019
- Published online by Cambridge University Press:
- 08 October 2019, e15
-
- Article
-
- You have access
- Export citation
DISTANCES BETWEEN FORMAL THEORIES
-
- Journal:
- The Review of Symbolic Logic / Volume 13 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 04 October 2019, pp. 633-654
- Print publication:
- September 2020
-
- Article
- Export citation
Iterative value models generation in the engineering design process
- Part of
-
- Journal:
- Design Science / Volume 5 / 2019
- Published online by Cambridge University Press:
- 04 October 2019, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE MODAL LOGIC OF SET-THEORETIC POTENTIALISM AND THE POTENTIALIST MAXIMALITY PRINCIPLES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 04 October 2019, pp. 1-35
- Print publication:
- March 2022
-
- Article
- Export citation
-
We analyze the precise modal commitments of several natural varieties of set-theoretic potentialism, using tools we develop for a general model-theoretic account of potentialism, building on those of Hamkins, Leibman and Löwe [14], including the use of buttons, switches, dials and ratchets. Among the potentialist conceptions we consider are: rank potentialism (true in all larger
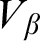 $V_\beta $), Grothendieck–Zermelo potentialism (true in all larger
$V_\beta $), Grothendieck–Zermelo potentialism (true in all larger 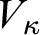 $V_\kappa $ for inaccessible cardinals
$V_\kappa $ for inaccessible cardinals 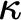 $\kappa $), transitive-set potentialism (true in all larger transitive sets), forcing potentialism (true in all forcing extensions), countable-transitive-model potentialism (true in all larger countable transitive models of ZFC), countable-model potentialism (true in all larger countable models of ZFC), and others. In each case, we identify lower bounds for the modal validities, which are generally either S4.2 or S4.3, and an upper bound of S5, proving in each case that these bounds are optimal. The validity of S5 in a world is a potentialist maximality principle, an interesting set-theoretic principle of its own. The results can be viewed as providing an analysis of the modal commitments of the various set-theoretic multiverse conceptions corresponding to each potentialist account.
$\kappa $), transitive-set potentialism (true in all larger transitive sets), forcing potentialism (true in all forcing extensions), countable-transitive-model potentialism (true in all larger countable transitive models of ZFC), countable-model potentialism (true in all larger countable models of ZFC), and others. In each case, we identify lower bounds for the modal validities, which are generally either S4.2 or S4.3, and an upper bound of S5, proving in each case that these bounds are optimal. The validity of S5 in a world is a potentialist maximality principle, an interesting set-theoretic principle of its own. The results can be viewed as providing an analysis of the modal commitments of the various set-theoretic multiverse conceptions corresponding to each potentialist account.
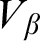
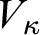
THREE CHARACTERIZATIONS OF STRICT COHERENCE ON INFINITE-VALUED EVENTS
-
- Journal:
- The Review of Symbolic Logic / Volume 13 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 04 October 2019, pp. 593-610
- Print publication:
- September 2020
-
- Article
- Export citation
Crowdsourcing evaluation of the quality of automatically generated questions for supporting computer-assisted language teaching
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Model-based systems engineering in modular design
- Part of
-
- Journal:
- Design Science / Volume 5 / 2019
- Published online by Cambridge University Press:
- 04 October 2019, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
MATHEMATICAL RIGOR AND PROOF
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 04 October 2019, pp. 409-449
- Print publication:
- June 2022
-
- Article
- Export citation
NONREPRESENTABLE RELATION ALGEBRAS FROM GROUPS - ADDENDUM
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 04 October 2019, p. 892
- Print publication:
- December 2019
-
- Article
- Export citation
4 - Frequency Hopping Approach
- from Part I - Indoor Locationing and Tracking
-
- Book:
- Wireless AI
- Published online:
- 27 September 2019
- Print publication:
- 03 October 2019, pp 66-89
-
- Chapter
- Export citation
22 - Heterogeneous Connections for IoT
- from Part V - IoT Connections
-
- Book:
- Wireless AI
- Published online:
- 27 September 2019
- Print publication:
- 03 October 2019, pp 583-604
-
- Chapter
- Export citation
Contents
-
- Book:
- Wireless AI
- Published online:
- 27 September 2019
- Print publication:
- 03 October 2019, pp vii-xii
-
- Chapter
- Export citation
Preface
-
- Book:
- Wireless AI
- Published online:
- 27 September 2019
- Print publication:
- 03 October 2019, pp xiii-xvi
-
- Chapter
- Export citation
2 - Centimeter-Accuracy Indoor Positioning
- from Part I - Indoor Locationing and Tracking
-
- Book:
- Wireless AI
- Published online:
- 27 September 2019
- Print publication:
- 03 October 2019, pp 19-38
-
- Chapter
- Export citation
