Refine search
Actions for selected content:
48196 results in Computer Science
Contents
-
- Book:
- Abstract Recursion and Intrinsic Complexity
- Published online:
- 23 November 2018
- Print publication:
- 06 December 2018, pp v-viii
-
- Chapter
- Export citation
3 - Complexity theory for recursive programs
- from Part I - Abstract (first order) recursion
-
- Book:
- Abstract Recursion and Intrinsic Complexity
- Published online:
- 23 November 2018
- Print publication:
- 06 December 2018, pp 103-126
-
- Chapter
- Export citation
Introduction
-
- Book:
- Abstract Recursion and Intrinsic Complexity
- Published online:
- 23 November 2018
- Print publication:
- 06 December 2018, pp 1-6
-
- Chapter
- Export citation
CARNAP’S DEFENSE OF IMPREDICATIVE DEFINITIONS
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 05 December 2018, pp. 372-404
- Print publication:
- June 2019
-
- Article
- Export citation
A NOTE ON RÉNYI'S ENTROPY RATE FOR TIME-INHOMOGENEOUS MARKOV CHAINS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 05 December 2018, pp. 579-590
-
- Article
- Export citation
ON DETERMINISTIC FINITE STATE MACHINES IN RANDOM ENVIRONMENTS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 05 December 2018, pp. 528-563
-
- Article
- Export citation
-
The general problem under investigation is to understand how the complexity of a system which has been adapted to its random environment affects the level of randomness of its output (which is a function of its random input). In this paper, we consider a specific instance of this problem in which a deterministic finite-state decision system operates in a random environment that is modeled by a binary Markov chain. The system interacts with it by trying to match states of inactivity (represented by 0). Matching means that the system selects the (t + 1)th bit from the Markov chain whenever it predicts at time t that the environment will take a 0 value. The actual value at time t + 1 may be 0 or 1 thus the selected sequence of bits (which forms the system's output) may have both binary values. To try to predict well, the system's decision function is inferred based on a sample of the random environment.
We are interested in assessing how non-random the output sequence may be. To do that, we apply the adapted system on a second random sample of the environment and derive an upper bound on the deviation between the average number of 1 bit in the output sequence and the probability of a 1. The bound shows that the complexity of the system has a direct effect on this deviation and hence on how non-random the output sequence may be. The bound takes the form of
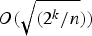 $O(\sqrt {(2^k/n} ))$ where 2k is the complexity of the system and n is the length of the second sample.
$O(\sqrt {(2^k/n} ))$ where 2k is the complexity of the system and n is the length of the second sample.
FREGE’S CONSTRAINT AND THE NATURE OF FREGE’S FOUNDATIONAL PROGRAM
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 05 December 2018, pp. 97-143
- Print publication:
- March 2019
-
- Article
- Export citation
-
Recent discussions on Fregean and neo-Fregean foundations for arithmetic and real analysis pay much attention to what is called either ‘Application Constraint’ (
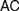 $AC$) or ‘Frege Constraint’ (
$AC$) or ‘Frege Constraint’ (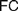 $FC$), the requirement that a mathematical theory be so outlined that it immediately allows explaining for its applicability. We distinguish between two constraints, which we, respectively, denote by the latter of these two names, by showing how
$FC$), the requirement that a mathematical theory be so outlined that it immediately allows explaining for its applicability. We distinguish between two constraints, which we, respectively, denote by the latter of these two names, by showing how 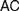 $AC$ generalizes Frege’s views while
$AC$ generalizes Frege’s views while 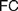 $FC$ comes closer to his original conceptions. Different authors diverge on the interpretation of
$FC$ comes closer to his original conceptions. Different authors diverge on the interpretation of 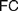 $FC$ and on whether it applies to definitions of both natural and real numbers. Our aim is to trace the origins of
$FC$ and on whether it applies to definitions of both natural and real numbers. Our aim is to trace the origins of 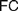 $FC$ and to explore how different understandings of it can be faithful to Frege’s views about such definitions and to his foundational program. After rehearsing the essential elements of the relevant debate (§1), we appropriately distinguish
$FC$ and to explore how different understandings of it can be faithful to Frege’s views about such definitions and to his foundational program. After rehearsing the essential elements of the relevant debate (§1), we appropriately distinguish 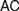 $AC$ from
$AC$ from 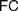 $FC$ (§2). We discuss six rationales which may motivate the adoption of different instances of
$FC$ (§2). We discuss six rationales which may motivate the adoption of different instances of 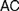 $AC$ and
$AC$ and 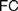 $FC$ (§3). We turn to the possible interpretations of
$FC$ (§3). We turn to the possible interpretations of 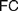 $FC$ (§4), and advance a Semantic
$FC$ (§4), and advance a Semantic 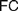 $FC$ (§4.1), arguing that while it suits Frege’s definition of natural numbers (4.1.1), it cannot reasonably be imposed on definitions of real numbers (§4.1.2), for reasons only partly similar to those offered by Crispin Wright (§4.1.3). We then rehearse a recent exchange between Bob Hale and Vadim Batitzky to shed light on Frege’s conception of real numbers and magnitudes (§4.2). We argue that an Architectonic version of
$FC$ (§4.1), arguing that while it suits Frege’s definition of natural numbers (4.1.1), it cannot reasonably be imposed on definitions of real numbers (§4.1.2), for reasons only partly similar to those offered by Crispin Wright (§4.1.3). We then rehearse a recent exchange between Bob Hale and Vadim Batitzky to shed light on Frege’s conception of real numbers and magnitudes (§4.2). We argue that an Architectonic version of 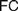 $FC$ is indeed faithful to Frege’s definition of real numbers, and compatible with his views on natural ones. Finally, we consider how attributing different instances of
$FC$ is indeed faithful to Frege’s definition of real numbers, and compatible with his views on natural ones. Finally, we consider how attributing different instances of 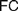 $FC$ to Frege and appreciating the role of the Architectonic
$FC$ to Frege and appreciating the role of the Architectonic 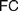 $FC$ can provide a more perspicuous understanding of his foundational program, by questioning common pictures of his logicism (§5).
$FC$ can provide a more perspicuous understanding of his foundational program, by questioning common pictures of his logicism (§5).
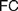
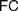
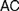
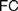
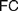
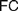
APPROXIMATION OF THE TAIL PROBABILITIES FOR BIDIMENSIONAL RANDOMLY WEIGHTED SUMS WITH DEPENDENT COMPONENTS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 34 / Issue 1 / January 2020
- Published online by Cambridge University Press:
- 05 December 2018, pp. 112-130
-
- Article
- Export citation
-
Let
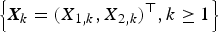 $\left\{ {{\bi X}_k = {(X_{1,k},X_{2,k})}^{\top}, k \ge 1} \right\}$ be a sequence of independent and identically distributed random vectors whose components are allowed to be generally dependent with marginal distributions being from the class of extended regular variation, and let
$\left\{ {{\bi X}_k = {(X_{1,k},X_{2,k})}^{\top}, k \ge 1} \right\}$ be a sequence of independent and identically distributed random vectors whose components are allowed to be generally dependent with marginal distributions being from the class of extended regular variation, and let 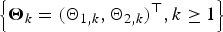 $\left\{ {{\brTheta} _k = {(\Theta _{1,k},\Theta _{2,k})}^{\top}, k \ge 1} \right\}$ be a sequence of nonnegative random vectors that is independent of
$\left\{ {{\brTheta} _k = {(\Theta _{1,k},\Theta _{2,k})}^{\top}, k \ge 1} \right\}$ be a sequence of nonnegative random vectors that is independent of 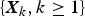 $\left\{ {{\bi X}_k, k \ge 1} \right\}$. Under several mild assumptions, some simple asymptotic formulae of the tail probabilities for the bidimensional randomly weighted sums
$\left\{ {{\bi X}_k, k \ge 1} \right\}$. Under several mild assumptions, some simple asymptotic formulae of the tail probabilities for the bidimensional randomly weighted sums 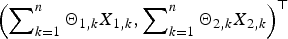 $\left( {\sum\nolimits_{k = 1}^n {\Theta _{1,k}} X_{1,k},\sum\nolimits_{k = 1}^n {\Theta _{2,k}} X_{2,k}} \right)^{\rm \top }$ and their maxima
$\left( {\sum\nolimits_{k = 1}^n {\Theta _{1,k}} X_{1,k},\sum\nolimits_{k = 1}^n {\Theta _{2,k}} X_{2,k}} \right)^{\rm \top }$ and their maxima 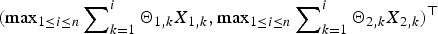 $({{\max} _{1 \le i \le n}}\sum\nolimits_{k = 1}^i {\Theta _{1,k}} X_{1,k},{{\max} _{1 \le i \le n}}\sum\nolimits_{k = 1}^i {\Theta _{2,k}} X_{2,k})^{\rm \top }$ are established. Moreover, uniformity of the estimate can be achieved under some technical moment conditions on
$({{\max} _{1 \le i \le n}}\sum\nolimits_{k = 1}^i {\Theta _{1,k}} X_{1,k},{{\max} _{1 \le i \le n}}\sum\nolimits_{k = 1}^i {\Theta _{2,k}} X_{2,k})^{\rm \top }$ are established. Moreover, uniformity of the estimate can be achieved under some technical moment conditions on 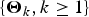 $\left\{ {{\brTheta} _k, k \ge 1} \right\}$. Direct applications of the results to risk analysis are proposed, with two types of ruin probability for a discrete-time bidimensional risk model being evaluated.
$\left\{ {{\brTheta} _k, k \ge 1} \right\}$. Direct applications of the results to risk analysis are proposed, with two types of ruin probability for a discrete-time bidimensional risk model being evaluated.
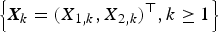
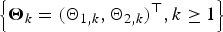
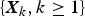
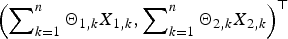
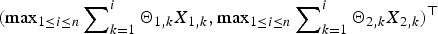
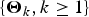
WINNER PLAYS STRUCTURE IN RANDOM KNOCKOUT TOURNAMENTS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 05 December 2018, pp. 500-510
-
- Article
- Export citation
Reward shaping for knowledge-based multi-objective multi-agent reinforcement learning
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 33 / 2018
- Published online by Cambridge University Press:
- 04 December 2018, e23
-
- Article
- Export citation
Efficiently Coupling the I-DLV Grounder with ASP Solvers
-
- Journal:
- Theory and Practice of Logic Programming / Volume 20 / Issue 2 / March 2020
- Published online by Cambridge University Press:
- 04 December 2018, pp. 205-224
-
- Article
- Export citation
-
We present
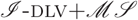 ${{{{$\mathscr{I}$}-}\textsc{dlv}}+{{$\mathscr{MS}$}}}$, a new answer set programming (ASP) system that integrates an efficient grounder, namely
${{{{$\mathscr{I}$}-}\textsc{dlv}}+{{$\mathscr{MS}$}}}$, a new answer set programming (ASP) system that integrates an efficient grounder, namely 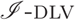 ${{{$\mathscr{I}$}-}\textsc{dlv}}$, with an automatic selector that inductively chooses a solver: depending on some inherent features of the instantiation produced by
${{{$\mathscr{I}$}-}\textsc{dlv}}$, with an automatic selector that inductively chooses a solver: depending on some inherent features of the instantiation produced by 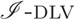 ${{{$\mathscr{I}$}-}\textsc{dlv}}$, machine learning techniques guide the selection of the most appropriate solver. The system participated in the latest (7th) ASP competition, winning the regular track, category SP (i.e., one processor allowed).
${{{$\mathscr{I}$}-}\textsc{dlv}}$, machine learning techniques guide the selection of the most appropriate solver. The system participated in the latest (7th) ASP competition, winning the regular track, category SP (i.e., one processor allowed).
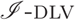
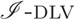
Q-Table compression for reinforcement learning
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 33 / 2018
- Published online by Cambridge University Press:
- 04 December 2018, e22
-
- Article
- Export citation
UNIFICATION IN SUPERINTUITIONISTIC PREDICATE LOGICS AND ITS APPLICATIONS
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 03 December 2018, pp. 37-61
- Print publication:
- March 2019
-
- Article
- Export citation
A survey of large-scale reasoning on the Web of data
-
- Journal:
- The Knowledge Engineering Review / Volume 33 / 2018
- Published online by Cambridge University Press:
- 03 December 2018, e21
-
- Article
- Export citation
Filling Sound with Space: An elemental approach to sound spatialisation
-
- Journal:
- Organised Sound / Volume 23 / Issue 3 / December 2018
- Published online by Cambridge University Press:
- 21 December 2018, pp. 296-307
- Print publication:
- December 2018
-
- Article
- Export citation
Theremin in the Press: Instrument remediation and code-instrument transduction
-
- Journal:
- Organised Sound / Volume 23 / Issue 3 / December 2018
- Published online by Cambridge University Press:
- 21 December 2018, pp. 256-269
- Print publication:
- December 2018
-
- Article
- Export citation
Staging the Kinetic: How music automata sensitise audiences to sound art
-
- Journal:
- Organised Sound / Volume 23 / Issue 3 / December 2018
- Published online by Cambridge University Press:
- 21 December 2018, pp. 235-245
- Print publication:
- December 2018
-
- Article
- Export citation
Editorial: Sound and kinetics – performance, artistic aims and techniques in electroacoustic music and sound art
-
- Journal:
- Organised Sound / Volume 23 / Issue 3 / December 2018
- Published online by Cambridge University Press:
- 21 December 2018, pp. 219-224
- Print publication:
- December 2018
-
- Article
-
- You have access
- HTML
- Export citation
OSO volume 23 issue 3 Cover and Front matter
-
- Journal:
- Organised Sound / Volume 23 / Issue 3 / December 2018
- Published online by Cambridge University Press:
- 21 December 2018, pp. f1-f2
- Print publication:
- December 2018
-
- Article
-
- You have access
- Export citation
