Refine search
Actions for selected content:
48207 results in Computer Science
Deep-learning-based macro-pixel synthesis and lossless coding of light field images
- Part of
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 8 / 2019
- Published online by Cambridge University Press:
- 17 July 2019, e20
- Print publication:
- 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Analysis and generation of laughter motions, and evaluation in an android robot
- Part of
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 8 / 2019
- Published online by Cambridge University Press:
- 25 January 2019, e6
- Print publication:
- 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Introspective Q-learning and learning from demonstration
- Part of
-
- Journal:
- The Knowledge Engineering Review / Volume 34 / 2019
- Published online by Cambridge University Press:
- 01 January 2019, e8
-
- Article
- Export citation
Semi-fragile speech watermarking based on singular-spectrum analysis with CNN-based parameter estimation for tampering detection
- Part of
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 8 / 2019
- Published online by Cambridge University Press:
- 16 April 2019, e11
- Print publication:
- 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Special issue on deep learning based detection and recognition for perceptual tasks with applications
- Part of
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 8 / 2019
- Published online by Cambridge University Press:
- 29 July 2019, e21
- Print publication:
- 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reliable multicast using remote direct memory access (RDMA) over a passive optical cross-connect fabric enhanced with wavelength division multiplexing (WDM)
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 8 / 2019
- Published online by Cambridge University Press:
- 23 October 2019, e25
- Print publication:
- 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Recent advances in video coding beyond the HEVC standard
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 8 / 2019
- Published online by Cambridge University Press:
- 25 June 2019, e18
- Print publication:
- 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Development of a computationally efficient voice conversion system on mobile phones
- Part of
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 8 / 2019
- Published online by Cambridge University Press:
- 04 January 2019, e4
- Print publication:
- 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Learning from past mistakes: improving automatic speech recognition output via noisy-clean phrase context modeling
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 8 / 2019
- Published online by Cambridge University Press:
- 01 February 2019, e8
- Print publication:
- 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ON OPTIMAL HETEROGENEOUS COMPONENTS GROUPING IN SERIES-PARALLEL AND PARALLEL-SERIES SYSTEMS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 28 December 2018, pp. 564-578
-
- Article
- Export citation
NATURAL AXIOMS FOR CLASSICAL MEREOLOGY
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 27 December 2018, pp. 201-208
- Print publication:
- March 2019
-
- Article
- Export citation
THE DEGREE PROFILE AND GINI INDEX OF RANDOM CATERPILLAR TREES
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 27 December 2018, pp. 511-527
-
- Article
- Export citation
ROB volume 37 issue 2 Cover and Back matter
-
- Article
-
- You have access
- Export citation
ON BOUNCING GEOMETRIC BROWNIAN MOTIONS
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 33 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 27 December 2018, pp. 591-617
-
- Article
- Export citation
1ML – Core and modules united
-
- Journal:
- Journal of Functional Programming / Volume 28 / 2018
- Published online by Cambridge University Press:
- 27 December 2018, e22
-
- Article
-
- You have access
- Export citation
INEFFABILITY AND REVENGE
-
- Journal:
- The Review of Symbolic Logic / Volume 13 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 27 December 2018, pp. 797-809
- Print publication:
- December 2020
-
- Article
- Export citation
ROB volume 37 issue 2 Cover and Front matter
-
- Article
-
- You have access
- Export citation
MODELS OF POSITIVE TRUTH
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 26 December 2018, pp. 144-172
- Print publication:
- March 2019
-
- Article
- Export citation
-
This paper is a follow-up to [4], in which a mistake in [6] (which spread also to [9]) was corrected. We give a strenghtening of the main result on the semantical nonconservativity of the theory of PT− with internal induction for total formulae
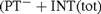 ${(\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}\left( {{\rm{tot}}} \right)$, denoted by PT− in [9]). We show that if to PT− the axiom of internal induction for all arithmetical formulae is added (giving
${(\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}\left( {{\rm{tot}}} \right)$, denoted by PT− in [9]). We show that if to PT− the axiom of internal induction for all arithmetical formulae is added (giving 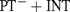 ${\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}$), then this theory is semantically stronger than
${\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}$), then this theory is semantically stronger than 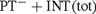 ${\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}\left( {{\rm{tot}}} \right)$. In particular the latter is not relatively truth definable (in the sense of [11]) in the former. Last but not least, we provide an axiomatic theory of truth which meets the requirements put forward by Fischer and Horsten in [9]. The truth theory we define is based on Weak Kleene Logic instead of the Strong one.
${\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}\left( {{\rm{tot}}} \right)$. In particular the latter is not relatively truth definable (in the sense of [11]) in the former. Last but not least, we provide an axiomatic theory of truth which meets the requirements put forward by Fischer and Horsten in [9]. The truth theory we define is based on Weak Kleene Logic instead of the Strong one.