Refine search
Actions for selected content:
48290 results in Computer Science
REC volume 29 issue 1 Cover and Front matter
-
- Article
-
- You have access
- Export citation
Storing massive Resource Description Framework (RDF) data: a survey
-
- Journal:
- The Knowledge Engineering Review / Volume 31 / Issue 4 / September 2016
- Published online by Cambridge University Press:
- 07 December 2016, pp. 391-413
-
- Article
- Export citation
Spatial awareness in pervasive ecosystems
-
- Journal:
- The Knowledge Engineering Review / Volume 31 / Issue 4 / September 2016
- Published online by Cambridge University Press:
- 07 December 2016, pp. 343-366
-
- Article
- Export citation
Saturated Graphs of Prescribed Minimum Degree
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 2 / March 2017
- Published online by Cambridge University Press:
- 07 December 2016, pp. 201-207
-
- Article
- Export citation
REC volume 29 issue 1 Cover and Back matter
-
- Article
-
- You have access
- Export citation
A universal model for growth of user population of products and services
-
- Journal:
- Network Science / Volume 4 / Issue 4 / December 2016
- Published online by Cambridge University Press:
- 07 December 2016, pp. 491-507
-
- Article
- Export citation
Existence of Spanning ℱ-Free Subgraphs with Large Minimum Degree
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 3 / May 2017
- Published online by Cambridge University Press:
- 07 December 2016, pp. 448-467
-
- Article
- Export citation
Planting Colourings Silently
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 3 / May 2017
- Published online by Cambridge University Press:
- 07 December 2016, pp. 338-366
-
- Article
- Export citation
-
Let k ⩾ 3 be a fixed integer and let Zk (G) be the number of k-colourings of the graph G. For certain values of the average degree, the random variable Zk (G(n, m)) is known to be concentrated in the sense that
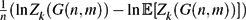 $\tfrac{1}{n}(\ln Z_k(G(n,m))-\ln\Erw[Z_k(G(n,m))])$ converges to 0 in probability (Achlioptas and Coja-Oghlan, Proc. FOCS 2008). In the present paper we prove a significantly stronger concentration result. Namely, we show that for a wide range of average degrees,
$\tfrac{1}{n}(\ln Z_k(G(n,m))-\ln\Erw[Z_k(G(n,m))])$ converges to 0 in probability (Achlioptas and Coja-Oghlan, Proc. FOCS 2008). In the present paper we prove a significantly stronger concentration result. Namely, we show that for a wide range of average degrees, 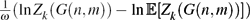 $\tfrac{1}{\omega}(\ln Z_k(G(n,m))-\ln\Erw[Z_k(G(n,m))])$ converges to 0 in probability for any diverging function
$\tfrac{1}{\omega}(\ln Z_k(G(n,m))-\ln\Erw[Z_k(G(n,m))])$ converges to 0 in probability for any diverging function 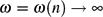 $\omega=\omega(n)\ra\infty$ . For k exceeding a certain constant k 0 this result covers all average degrees up to the so-called condensation phase transitiond k,con , and this is best possible. As an application, we show that the experiment of choosing a k-colouring of the random graph G(n,m) uniformly at random is contiguous with respect to the so-called ‘planted model’.
$\omega=\omega(n)\ra\infty$ . For k exceeding a certain constant k 0 this result covers all average degrees up to the so-called condensation phase transitiond k,con , and this is best possible. As an application, we show that the experiment of choosing a k-colouring of the random graph G(n,m) uniformly at random is contiguous with respect to the so-called ‘planted model’.
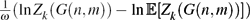
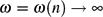
Factors of IID on Trees
-
- Journal:
- Combinatorics, Probability and Computing / Volume 26 / Issue 2 / March 2017
- Published online by Cambridge University Press:
- 06 December 2016, pp. 285-300
-
- Article
- Export citation
Connections in Randomly Oriented Graphs
-
- Journal:
- Combinatorics, Probability and Computing / Volume 27 / Issue 4 / July 2018
- Published online by Cambridge University Press:
- 06 December 2016, pp. 667-671
-
- Article
- Export citation
ANALYTIC CUT AND INTERPOLATION FOR BI-INTUITIONISTIC LOGIC
-
- Journal:
- The Review of Symbolic Logic / Volume 10 / Issue 2 / June 2017
- Published online by Cambridge University Press:
- 06 December 2016, pp. 259-283
- Print publication:
- June 2017
-
- Article
- Export citation
Jump from parallel to sequential proofs: exponentials
-
- Journal:
- Mathematical Structures in Computer Science / Volume 28 / Issue 7 / August 2018
- Published online by Cambridge University Press:
- 05 December 2016, pp. 1204-1252
-
- Article
- Export citation
Transport of finiteness structures and applications
-
- Journal:
- Mathematical Structures in Computer Science / Volume 28 / Issue 7 / August 2018
- Published online by Cambridge University Press:
- 05 December 2016, pp. 1061-1096
-
- Article
- Export citation

Wireless-Powered Communication Networks
- Architectures, Protocols, and Applications
-
- Published online:
- 01 December 2016
- Print publication:
- 17 November 2016
4 - An Algebraic Method for Constructing QC-PTG-LDPC Codes and Code Ensembles
-
- Book:
- LDPC Code Designs, Constructions, and Unification
- Published online:
- 15 December 2016
- Print publication:
- 01 December 2016, pp 21-40
-
- Chapter
- Export citation
9 - SP-Construction of Spatially Coupled QC-LDPC Codes
-
- Book:
- LDPC Code Designs, Constructions, and Unification
- Published online:
- 15 December 2016
- Print publication:
- 01 December 2016, pp 111-137
-
- Chapter
- Export citation
